이 게시글은 기계 학습과 기계 학습 모두에 새롭게 등장하는 독자를 위한 것입니다.
MNIST가 무엇인지 이미 알고 있다면 softmax( multinomial logistic)회귀이 무엇인지를 알 수 있으며, 이는 보다 빠른 속도의 자습서를 선호할 수 있습니다.
튜토리얼을 시작하기 전에 반드시 TensorFlow를 설치해야 합니다.
프로그래밍하는 법을 배울 때,"HelloWorld"는 "HelloWorld"를 인쇄하는 것과 같은 전통을 가지고 있습니다. 프로그래밍이 HelloWorld를 하는 것은 이번 튜토리얼과 같은 문맥입니다.
MNIST는 간단한 컴퓨터 비전 데이터 세트입니다. 이는 다음과 같이 손으로 작성한 숫자의 이미지로 구성됩니다.
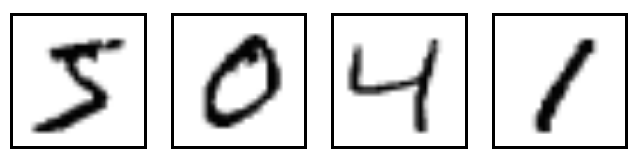
또한 각 이미지에 대한 라벨이 포함되어 있으며, 각 이미지에 해당하는 숫자를 알려 줍니다.
예를 들어 위 이미지의 레이블은 5,0,4,1입니다.
이 튜토리얼에서, 우리는 이미지를 관찰하고 그들이 어떤 숫자인지 예측할 수 있도록 모델을 훈련시킬 것입니다.
우리의 목표는 최첨단 성능을 발휘하는 정교한 모델을 훈련시키는 것이 아니라, 나중에 할 수 있도록 코드를 부여하는 것입니다!--하지만 발가락을 사용하여 발가락 부분을 찍는 것이 낫다.
이와 같이 우리는 매우 단순한 모델로 시작할 것입니다. 바로 Softmax 회귀라는 회귀 모델입니다.
+ 즉, 나중에 훈련시킨 모델들을 가져오는 원리들을 파악 및 softmax 회귀 모델을 알아가는 부분인 것 같습니다.
이 튜토리얼의 실제 코드는 매우 짧으며, 모든 재미 있는 것들은 세줄로 되어 있습니다.하지만, 그것 이면의 아이디어들을 이해하는 것은 매우 중요하다.이것 때문에, 우리는 매우 신중하게 코드를 완성할 것입니다.
본 자습서는 mnist_softmax.py 라인 코드에서 발생하는 일련의 설명, 라인별로 설명합니다.
본 자습서는 다음을 비롯하여 몇가지 다른 방법으로 사용할 수 있습니다.
1) 각 줄의 설명을 통해 읽을 수 있는 대로 각 코드를 라인별로 구분하여 라인 업으로 복사하고 붙여 넣으십시오.
2) 설명서를 읽기 전에 전체 mnist_softmax.py Python 파일을 실행하고 이 자습서를 사용하여 명확하지 않은 코드를 이해할 수 있도록 합니다.
수행할 내용:
1)데이터 중복 제거 기술에 대한 자세한 내용 및 데이터 중복 제거 기술에 대해 알아보기.
2)이미지의 모든 픽셀을 보는 데 기반하여 자릿수를 인식하는 기능을 생성합니다.
3)TensorFlow를 사용하여 모델을 " 보기"로 인식하여 모델을 식별하고, 수천개의 예제를 실행할 수 있도록 합니다.
4)테스트 데이터를 통해 모델의 정확도를 점검하십시오.
The MNIST Data
MNIST 데이터는 Yann LeCun의 웹 사이트에서 호스팅 됩니다.
이 자습서에서 코드를 복사하고 붙여 넣는 경우, 여기서 데이터를 자동으로 다운로드하고 읽을 수 있는 코드 두줄로 시작하십시오.
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)MNIST 데이터는 세 부분으로 나뉩니다. 즉, 교육 데이터의 55,000개의 데이터 포인트( mnist.train), 테스트 데이터의 10,000포인트( mnist.test), 검증 데이터의 5,000포인트( mnist.validation)등이 있습니다.
이 세분류는 매우 중요합니다. 우리가 배워야 할 것은 우리가 배우지 못한 것을 확실히 할 수 있는 별개의 데이터를 가지고 있다는 것입니다.
앞서 언급한 바와 같이, 모든 MNIST 데이터 포인트에는 두개의 파트가 있습니다. 즉, 손으로 작성한 숫자와 해당 라벨의 이미지입니다.
우리는 이미지"x"와 라벨"y"를 부를 것입니다. 교육 세트 및 테스트 세트에는 이미지 및 해당 라벨이 모두 포함되어 있습니다. 예를 들어 교육용 이미지는 mnist.train.images이며, 교육용 레이블은 mnist.train.labels.입니다.
각 이미지는 28픽셀 x28픽셀입니다. NAT은 다음과 같은 다양한 수치로 해석할 수 있습니다.
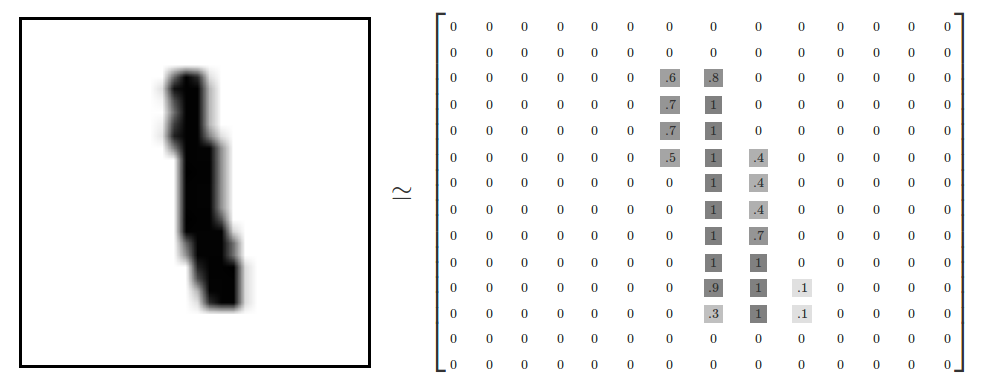
우리는 이 배열을 28x28의 벡터의 벡터로 평평하게 만들 수 있다. 우리가 이미지들 사이에 일관성을 유지하는 한, 우리가 어떻게 배열할지는 중요하지 않습니다.
이러한 관점에서 볼 때, MNIST 이미지는 매우 풍부한 구조(경고:시각화 집약적 시각화)를 가진 벡터 기반 벡터 공간의 수많은 포인트일 뿐입니다.
평평한 데이터에서 이미지의 2D구조에 대한 정보가 삭제됩니다. 최고의 컴퓨터 비전 방법은 이 구조를 이용하는 거죠. 그리고 우리는 나중에 튜토리얼을 쓸 것입니다. 그러나 우리가 여기서 사용할 간단한 방법은 다음과 같습니다.
결과적으로 mnist.train.images는 55000( n-dimensional, 784, ])의 텐서이다. 첫번째 차원은 영상 목록에 있는 색인이며 두번째 차원은 각 영상의 각 픽셀에 대한 인덱스입니다.텐서( tensor)의 각 항목은 특정 영상의 특정 화소에 대해 0과 1사이의 화소 강도이다.

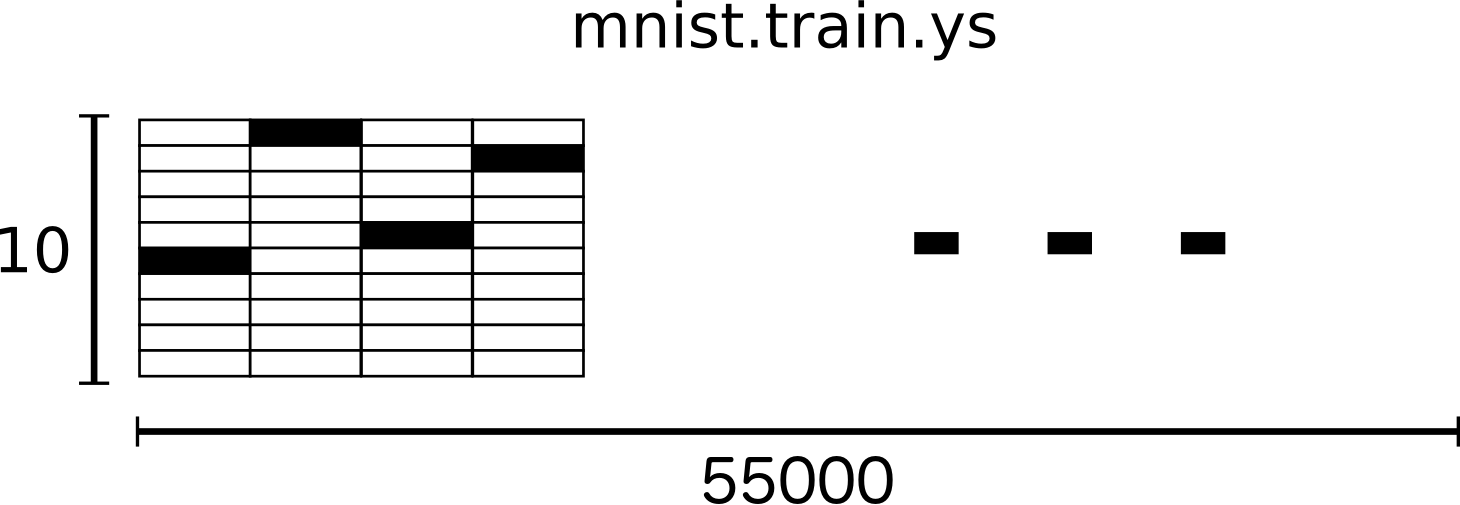
각 그림 MNIST의 각 이미지에는 해당 이미지에 그려진 숫자를 나타내는 0~9사이의 숫자가 있습니다.
본 자습서를 위해 저희는 라벨을 "one-hot 벡터"라고 부르고자 합니다. 벡터 기반 벡터는 대부분의 차원에서 0이며, 단일 차원의 1차원이다. 이 경우 n번째 숫자는 n번째 치수의 1개의 벡터로 표현됩니다.예를 들어, 3은[0,0,0,0,0,0,0,0,0,0]입니다. 결과적으로 mnist.train.labels는[ 55000,10]kg의 부동 소수 점 배열이다.
우리는 이제 실제로 모델을 만들 준비가 됐어요!
Softmax Regressions
파이썬을 사용하여 효율적인 숫자 계산을 하기 위해서, 우리는 보통 Python곱셈기와 같은 비싼 작업을 하는 NumPy 같은 라이버리을 사용한다. 다른 언어로 구현된 매우 효율적인 코드이다.
불행히도, 모든 운영 체제로 전환하는 데는 여전히 많은 오버 헤드가 존재할 수 있습니다.
이 오버 헤드는 특히 데이터 전송에 높은 비용이 들 수 있는 분산된 방식이나 분산된 방식으로 계산하려는 경우에 특히 나쁩니다.
TensorFlow는 또한 Python을 없애기 위해 많은 노력을 하지만, 이러한 오버 헤드를 피하기 위해 한 걸음 더 나아 간다.
Python은 파이썬을 사용하여 독립적으로 운영하는 것을 대신하는 대신에 파이선을 사용하여 운영되는 상호 작용 작업의 그래프에 대해 설명합니다.(이와 같은 접근 방식은 몇개의 기계 학습 라이브러리에서 볼 수 있습니다.)
TensorFlow를 사용하려면 먼저 가져와야 합니다.
import tensorflow as tfimport tensorflow as tf우리는 상징적 변수를 조작하여 이러한 상호 작용 운영을 설명한다. 다음을 생성합니다.
x = tf.placeholder(tf.float32, [None, 784])x는 특정한 가치가 아니다. 이것은 자리 표시자입니다. 우리가 계산대에서 계산할 때 우리가 입력할 가치가 있는 값입니다.
우리는 각각의 MNIST 이미지들을 784-dimensional 벡터로 바꿀 수 있는 숫자를 입력할 수 있기를 원합니다.
우리는 이것을 부동 소수 점 이하의 부동 소수 점 숫자의 2차원 텐서( 784)로 표현한다. (여기서는 치수가 어떤 길이라도 될 수 있음을 의미한다.)
우리는 또한 모델에 대한 체중(Weights)과 편견(Biases)이 필요합니다. 우리는 이것들을 추가 투입하는 것을 상상할 수 있지만, TensorFlow는 그것을 다루는 더 나은 방법을 가지고 있습니다. Variable
Variable는 상호 작용의 상호 작용에 대한 TensorFlow의 그래프에서 수정 가능한 수정 가능한 텐서이다.
그것은 계산에 의해 사용되고 심지어 수정될 수도 있다. 기계 학습 애플리케이션의 경우 일반적으로 모델 매개 변수는 변수 변수가 됩니다.
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))우리는 변수의 초기 값을 tf.Variable의 초기 값으로 줌으로써 이 변수를 생성합니다. 이 경우에는 W과 b을 tf.zeros 0으로 나눕니다.
우리는 W와 b를 배울 것이기 때문에, 그것들이 처음에는 그다지 중요하지 않다.
W는[ 784,10]의 형태를 가지고 있습니다. 왜냐하면 우리는 벡터의 벡터 벡터를 곱하기 위해 다른 등급의 벡터 벡터를 생성하기 위해 벡터 벡터를 곱하고 싶습니다.b는 출력에 추가할 수 있도록[10]의 모양을 가지고 있다.
이제 모델을 구현할 수 있습니다. 그것을 정의하는데 한줄만 걸려요!
y = tf.nn.softmax(tf.matmul(x, W) + b)첫째로, 우리는 x, W, W의 표현으로 x를 곱합니다.
이것은 우리가 곱셈 부호를 가지고 있는 우리의 방정식으로, 우리가 여러개의 입력을 가진 2D텐서를 다루는 작은 속임수로 우리의 방정식에 넣은 것에서 힌트를 얻었다.
그리고 나서 우리는 b를 추가하고, 마침내 tf.nn.softmax.를 적용한다.
바로 그거에요. 몇번의 짧은 설치 후에 모델을 정의할 수 있는 선이 하나밖에 없었습니다.
그것은 TensorFlow가 특별히 쉽게 회귀할 수 있도록 설계되었기 때문이 아니다.
그것은 기계 학습 모델에서부터 물리학 시뮬레이션에 이르기까지 많은 숫자의 수치 연산을 묘사하는 매우 유연한 방법입니다.
그리고 일단 정의된 대로, 우리의 모델은 컴퓨터의 CPU, GPUs, 심지어는 심지어 전화기로도 작동할 수 있습니다!
Training
모델을 훈련시키기 위해서, 우리는 모델이 좋은 것이 무엇인지를 의미하는 것을 정의해야 합니다.
실제로, 기계 학습에서는 전형적으로 모델이 나쁘다는 것을 의미합니다.
우리는 이것을 원가 혹은 손실이라 부르며, 그것은 우리의 모델이 원하는 결과로부터 얼마나 멀리 떨어져 있는지를 나타냅니다.
우리는 에러를 최소화하려고 합니다. 에러 마진이 적을수록 우리의 모델은 더 좋습니다.
모델의 분실을 결정하기 위한 매우 일반적이고 매우 훌륭한 기능은 "cross-entropy"라고 불립니다.
정보 이론은 정보 이론에서 정보 압축 코드에 대해 생각하는 것에서 기인하지만, 도박에서부터 기계 학습에 이르기까지 많은 분야에서 중요한 아이디어가 된다. 다음과 같이 정의됩니다.

여기서 y는 예측 가능한 확률 분포이며 y ′는 실제 분포(자릿수 라벨을 사용한 one-hot 벡터)이다.
대략적으로, cross-entropy는 우리의 예측이 진실을 설명하는 데 얼마나 비효율적인지를 측정하고 있다.
cross-entropy에 대한 자세한 내용은 본 자습서의 범위를 벗어나지만 이해할 만한 가치가 충분히 있습니다.
cross-entropy를 구현하려면 먼저 새 자리 표시자를 추가하여 올바른 답을 입력해야 합니다.
y_ = tf.placeholder(tf.float32, [None, 10])우리는 cross-entropy 기능을 구현할 수 있다. :
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))첫째, tf.log는 y의 각 요소의 대수를 계산한다. 다음으로 y-y의 원소를 곱하고 y^y(y)와 같은 원소를 곱한다.
그런 다음 tf.reduce_sum는 reduction_indices=[1 매개 변수로 인해 y의 두번째 치수에 해당하는 요소를 추가합니다.
마지막으로, tf.reduce_mean는 배치의 모든 예제에 대한 평균을 계산합니다.
소스 코드에서는 이 공식을 사용하지 않습니다. 숫자가 불안정하기 때문입니다. 그 대신에 unnormalized(x, W)+b(x, W)에 softmax_cross_entropy_with_logits를 tf.nn.softmax_cross_entropy_with_logits에 적용한다.
이는 보다 수치적으로 안정적인 기능을 통해 내부적으로 softmax 활성화를 계산합니다. 코드를 사용하는 경우 대신 tf.nn.softmax_cross_entropy_with_logits를 사용하는 것을 고려해 보십시오.
이제 우리가 원하는 것이 무엇인지 알 수 있으므로, 우리가 그것을 하기 위해 TensorFlow를 훈련시키는 것은 매우 쉬워요.
왜냐하면 TensorFlow는 당신의 계산의 전체 그래프를 알고 있기 때문입니다. 자동화 알고리즘을 사용하여 변수가 손실되는 손실에 어떻게 영향을 미치는지 효율적으로 결정할 수 있습니다.
그런 다음 최적화 알고리즘을 적용하여 변수를 수정하고 손실을 줄일 수 있습니다.
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)이 경우에, 우리는 TensorFlow에게 0.5의 학습 속도로 구배 하강 알고리즘을 사용하여 cross_entropy를 최소화할 것을 요청한다.경사 하강은 간단한 절차입니다. 여기서 TensorFlow는 단순히 각 변수를 비용을 감소시키는 방향으로 조금씩 돌립니다. 하지만 TensorFlow는 여러가지 다른 최적화 알고리즘을 제공합니다. 만약 한개만 한다면 하나의 선을 조정하는 것만큼 간단합니다.
TensorFlow가 실제로 여기서 수행하는 것은 backpropagation와 경사도 하강을 구현하는 그래프에 새로운 연산을 추가하는 것입니다. 그런 다음, 단일 작업을 수행합니다. 단, 작동 시 기울기 하강 훈련을 수행하여 변수를 약간 수정하고 손실을 줄입니다.
이제 InteractiveSession에서 모델을 시작할 수 있습니다.
sess = tf.InteractiveSession()먼저 생성한 변수를 초기화하기 위한 작업을 생성해야 합니다.
tf.global_variables_initializer().run()훈련을 시작합시다--훈련 스텝은 1000번입니다!
for _ in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})각 단계마다 100개의 무작위 데이터 포인트가 배치되어 있습니다. 교육 세트에서 백개의 랜덤 데이터 포인트를 얻을 수 있습니다. 우리는 배치 데이터에서 자리 표시자를 대체하기 위해 train_step 데이터를 실행한다.
무작위 데이터의 소량 배치를 확률적 훈련이라 부르며 이 경우 확률적 경사 하강 하강이다. 이상적으로는, 우리는 모든 훈련 과정을 위해 모든 데이터를 사용하고 싶습니다. 왜냐하면 우리는 우리가 해야 할 일을 더 잘 이해할 수 있기 때문입니다. 하지만 그것은 비쌉니다. 따라서, 우리는 매번마다 다른 하위 집합을 사용합니다. 이것을 하는 것은 싸고 이로운 점도 많다.
Evaluating Our Model
우리의 모델은 얼마나 잘 되나요?
글쎄요, 우선 정확한 라벨을 어디에 뒀는지 알아냅시다. tf.argmax는 어떤 축을 따라 가장 높은 진입률의 지수를 나타내는 매우 유용한 기능이다. 예를 들어, tf.argmax(y, 1)은 각 입력에 대해 가장 가능성이 높은 라벨이며, tf.argmax(y_, 1)은 정확한 라벨로 표시된다. 우리는 우리의 예측이 진실과 일치하는지를 확인하기 위해 tf.equal를 사용할 수 있다.
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))그것은 우리에게 booleans 리스트를 제공한다. 정확한 비율을 결정하기 위해, 우리는 부동 소수 점 숫자를 선택한 다음 평균을 취한다. 예를 들어,[True, False, True, True]는 0.75가 될[1,0,1,1]이 됩니다.
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))마지막으로, 우리는 우리의 시험 데이타에 대한 정확성을 요구한다.
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))이는 약 92%여야 합니다.
good ? 어떤가요? 글쎄, 그렇진 않아. 사실, 그것은 꽤나 나빠요. 이것은 우리가 매우 단순한 모델을 사용하고 있기 때문입니다.
약간의 깊이를 가지고 있으면 97%까지 갈 수 있어요. 최고의 모델들은 99.7%이상의 정확도를 달성할 수 있습니다! ( 자세한 내용은 이 결과 목록을 참조하십시오.)
중요한 것은 우리가 이 모델에서 배운 것입니다. 그럼에도 불구하고, 만약 여러분이 이러한 결과에 대해 조금 더 우울하다면, 우리가 훨씬 더 잘하는 다음 튜토리얼을 통해 더 정교한 모델을 만드는 방법을 배워 보세요!
출처 : https://www.tensorflow.org/get_started/mnist/beginners
추후 다음 튜토리얼을 하기 전에 실제 돌린 장면을 포함해서 올리도록 하겠습니다.
'Computer_IT > tensorflow' 카테고리의 다른 글
| Deep MNIST for Experts ( 히든 레이어 버전) (0) | 2017.06.30 |
|---|---|
| [인공지능] Tensorflow 프로그래머 가이드부터 다시 시작하자. (0) | 2017.06.22 |
| [인공지능] tensorflow 시작 튜토리얼 2 : tf.train API (0) | 2017.06.05 |
| [인공지능] TensorFlow 시작하기 (설치 이후 첫 튜토리얼) (0) | 2017.05.22 |
| 인공지능의 입문 Tensorflow를 설치해보자. (0) | 2017.05.04 |