오늘 이슈 뉴스를 요약해드리겠습니다. 다음은 10개의 주요 뉴스입니다.
- 정부, 일본 기시다 야스쿠니 공물 봉납에 "깊은 실망·유감"…전범 합사에 공물을 봉납한 일본 총리에 대해 강력한 항의를 표명했습니다.¹
- 이스라엘 대피 작전에 참여한 한국인들이 긴박한 상황을 전했습니다. 이스라엘과 팔레스타인의 충돌로 인해 이륙 순간에도 폭발음이 계속 들렸다고 말했습니다.²
- 위안부·세월호 피해지원 단체 일부가 국고보조금을 횡령·부정사용한 것으로 감사원이 조사했습니다. 단체들은 보조금을 개인 용도로 사용하거나 적절한 증빙을 제공하지 않았습니다.³
- 내일 아침에도 가을 추위가 이어집니다. 전국 대부분 지역에서 기온이 5도 내외로 내려갈 것으로 예상됩니다. 안개와 강풍에 주의하시기 바랍니다.⁴
- 수원에서 전세사기 의혹을 받는 임대인의 모습이 드러났습니다. 임대인은 전세계약서를 위조하고, 보증금을 받아 도망간 혐의를 받고 있습니다. 피해자들은 돈을 돌려달라고 요구하고 있습니다.
- 요르단 국왕이 팔레스타인 난민 수용에 한계가 있다고 밝혔습니다. 이집트와 요르단은 이미 수백만 명의 난민을 수용하고 있으며, 더 이상의 부담은 감당할 수 없다고 말했습니다.
- 김재열 국제빙상연맹회장이 역대 12번째 한국인 국제올림픽위원회 위원으로 선출되었습니다. 김재열 회장은 2023년 12월까지 임기를 가집니다.
- 복지부 장관이 의사 수 증원을 더 이상 미룰 수 없다고 주장했습니다. 의사 수 증원은 공공의료 인력 확보와 지역 의료 격차 해소를 위해 필요하다고 말했습니다.
- 한동훈 전 법무부 차관이 돌려차기 피해자와 통화하며 사과했습니다. 한동훈 전 차관은 보복협박 재발을 방지할 것이라고 약속했습니다.
- 유류세 인하가 연말까지 연장됩니다. 유류세 인하로 인해 휘발유는 25%, 경유는 37% 가격이 낮아집니다.
출처: Bing과의 대화, 2023. 10. 20.
(1) 이슈 메인 - SBS 뉴스. https://news.sbs.co.kr/news/newsHotIssue.do.
(2) 주요뉴스 | 연합뉴스. https://www.yna.co.kr/theme/headlines-history.
(3) 오늘의 이슈 - Remember Now. https://now.rememberapp.co.kr/category/%ec%98%a4%eb%8a%98%ec%9d%98-%ec%9d%b4%ec%8a%88/.
(4) 홈 : 네이트 뉴스. https://news.nate.com/.
인공지능
- 인공지능 활용 오늘의 뉴스[2023.10.27] 2023.10.20
- 2024년을 주도할 5가지 혁신적인 기술 트렌드 2023.10.18
- [텐서플로우]인공지능 들여다보기(그래프 보기)Tensorboard) 2017.12.08
- tf.estimator로 입력 함수 작성하기 2017.11.24
- 가트너 2018 기술 동향 TOP 10 2017.10.17
- [텐서플로우] CSV 활용하기/ 간단한 판별 AI 만들기 2017.10.10
- TensorFlow Mechanics 101 2017.08.24
- Deep MNIST for Experts ( 히든 레이어 버전) 2017.06.30
- [인공지능] Tensorflow 프로그래머 가이드부터 다시 시작하자. 2017.06.22
- [인공지능] 초급 손글씨 판별하기 (MNIST For ML Beginners) 2017.06.14
인공지능 활용 오늘의 뉴스[2023.10.27]
2024년을 주도할 5가지 혁신적인 기술 트렌드

2024년은 혁신과 변화의 시대로 예측되며, 다양한 기술 트렌드가 우리의 삶과 사회에 큰 영향을 미칠 것으로 예상됩니다. 이 글에서는 2024년을 주도할 5가지 혁신적인 기술 트렌드에 대해 알아보겠습니다.
1. 인공지능(AI)과 자동화: AI는 계속해서 발전하고 있으며, 2024년에는 더욱 놀라운 성과를 보여줄 것으로 예상됩니다. AI를 활용한 자동화 기술은 다양한 산업 분야에서 일자리 변화와 생산성 향상을 가져올 것으로 전망됩니다.
2. 사물 인터넷(IoT)와 스마트 환경: IoT는 우리 주변의 모든 장치들이 인터넷에 연결되어 데이터를 교환하는 개념입니다. 2024년에는 스마트 시티, 스마트 홈, 스마트 건축물 등에서 IoT가 더욱 발전하여 우리의 생활을 편리하게 만들어 줄 것으로 예상됩니다.
3. 가상현실(VR)과 증강현실(AR): VR과 AR은 우리의 경험을 혁신시키고 상호작용하는 방식을 변화시킬 것입니다. 게임 산업부터 교육 및 엔터테인먼트 분야까지 VR과 AR이 점차 보급되면서 생활 속 여러 영역에서 창조적인 경험을 제공할 수 있게 될 것입니다.
4. 사이버 보안: 디지털 공간에서의 위협은 계속해서 증가하고 있습니다. 따라서 사이버 보안 기술은 더욱 중요해질 것으로 예상됩니다. 2024년에는 보다 강력한 암호화 기술 및 침입 탐지 시스템 등이 개발되어 개인정보와 비즈니스 데이터를 보호하는 역할을 할 것입니다.
5. 자율 주행 차량: 자율 주행 차량은 계속해서 발전하고 있으며, 2024년에는 상용화 단계로 진입할 것으로 전망됩니다. AI와 센서 기술의 발전으로 안전성과 효율성이 개선되며, 운전자 없이 스스로 주행하는 차량들이 도로 위에서 일상적인 모습이 될 가능성이 큽니다.
위 5가지 기술 트렌드는 2024년에 크게 부상할 전망이며, 우리의 일상 생활 및 사회 구조에 크게 영향을 줄 것으로 예상됩니다.
[텐서플로우]인공지능 들여다보기(그래프 보기)Tensorboard)
TensorBoard: Visualizing Learning
(TensorBoard : 학습 시각화)
기계학습이 어떻게 하는지 시각적으로 볼 수 있는 라이브러리입니다.
거대한 심 신경 네트워크를 훈련하는 것처럼 TensorFlow를 사용할 계산은 복잡하고 혼란 스러울 수 있습니다. TensorFlow 프로그램을 더 쉽게 이해하고 디버깅하고 최적화하기 위해 TensorBoard라는 시각화 도구 모음을 포함 시켰습니다. TensorBoard를 사용하여 TensorFlow 그래프를 시각화하고 그래프 실행에 대한 정량적 메트릭을 플롯하고 통과 한 이미지와 같은 추가 데이터를 표시 할 수 있습니다. TensorBoard가 완전히 구성되면 다음과 같이 표시됩니다.
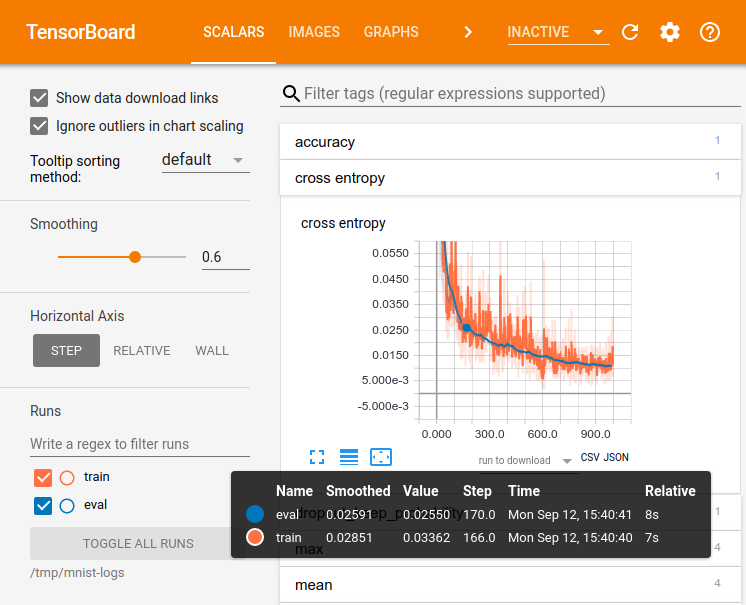
이 자습서는 간단한 TensorBoard 사용법을 배우기위한 것입니다. 다른 리소스도 있습니다. TensorBoard의 GitHub(TensorBoard's GitHub)에는 팁 및 트릭 및 디버깅 정보를
포함하여 TensorBoard 사용에 대한 더 많은 정보가 있습니다.
Serializing the data
데이터 직렬화
TensorBoard는 TensorFlow를 실행할 때 생성 할 수있는 요약 데이터가 포함 된 TensorFlow 이벤트 파일을 읽음으로써 작동합니다. 다음은 TensorBoard 내의 요약 데이터에 대한 일반적인 수명주기입니다.
먼저 요약 데이터를 수집 할 TensorFlow 그래프를 만들고 요약 작업으로 주석(summary operations)을 추가 할 노드를 결정합니다.
예를 들어, MNIST 자리를 인식 할 수있는 길쌈 신경 네트워크를 학습한다고 가정합니다. 학습 속도가 시간에 따라 어떻게 변하는 지, 그리고 목적 함수가 어떻게 변하는지를 기록하고 싶습니다. 학습 속도와 손실을 각각 출력하는 노드에 tf.summary.scalar op를 연결하여이를 수집합니다. 그런 다음 각 스칼라 요약에 '학습률'또는 '손실 함수'와 같은 의미있는 태그를 지정합니다.
특정 레이어에서 나오는 활성화 분포 또는 그라데이션이나 가중치의 분포를 시각화하고 싶을 수도 있습니다. tf.summary.histogram ops를 그라디언트 출력과 가중치를 유지하는 변수에 각각 첨부하여이 데이터를 수집합니다.
사용 가능한 모든 요약 작업에 대한 자세한 내용은 요약 작업에 대한 문서를 확인하십시오.
TensorFlow의 작업은 실행하기 전까지는 아무 것도하지 않거나 출력에 의존하는 연산을 수행합니다. 방금 작성한 요약 노드는 그래프의 주변 장치입니다. 현재 실행중인 작업 단위는 모두 해당 노드에 의존하지 않습니다. 따라서 요약을 생성하려면 이러한 모든 요약 노드를 실행해야합니다. 손으로 직접 관리하는 것은 지루할 수 있으므로 tf.summary.merge_all을 사용하여 모든 요약 데이터를 생성하는 단일 op로 결합하십시오.
그런 다음 병합 된 요약 연산을 실행하면 주어진 단계에서 모든 요약 데이터가있는 직렬화 된 요약 protobuf 객체가 생성됩니다. 마지막으로이 요약 데이터를 디스크에 기록하려면 summary protobuf를 tf.summary.FileWriter에 전달하십시오.
FileWriter는 생성자에서 logdir을 사용합니다.이 logdir은 모든 이벤트가 기록되는 디렉토리입니다. 또한 FileWriter는 선택적으로 생성자에서 Graph를 가져올 수 있습니다. Graph 객체를 받으면 TensorBoard는 텐서 모양 정보와 함께 그래프를 시각화합니다. 이렇게하면 그래프를 통해 흐르는 것이 훨씬 잘 전달됩니다 : Tensor 모양 정보( Tensor shape information)를 참조하십시오.
이제 그래프를 수정하고 FileWriter를 만들었으므로 네트워크를 시작할 준비가되었습니다! 원하는 경우 매 단계마다 병합 된 요약 작업을 실행하고 많은 양의 교육 데이터를 기록 할 수 있습니다. 그것은 당신이 필요로하는 것보다 더 많은 데이터 일 것 같다. 대신 병합 된 요약 연산을 n 단계마다 실행하는 것을 고려하십시오.
아래의 코드 예제는 간단한 MNIST 튜토리얼을 수정 한 것으로서 몇 가지 요약 작업을 추가하고 10 단계마다 실행합니다. 이것을 실행하고 tensorboard --logdir = / tmp / tensorflow / mnist를 실행하면 훈련 도중 가중치 나 정확도가 어떻게 변화했는지와 같은 통계를 시각화 할 수 있습니다. 아래의 코드는 발췌 한 것입니다. 전체 소스가 여기(here)에 있습니다.
def variable_summaries(var):
"""Attach a lot of summaries to a Tensor (for TensorBoard visualization)."""
with tf.name_scope('summaries'):
mean = tf.reduce_mean(var)
tf.summary.scalar('mean', mean)
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('stddev', stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
tf.summary.histogram('histogram', var)
def nn_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu):
"""Reusable code for making a simple neural net layer.
It does a matrix multiply, bias add, and then uses relu to nonlinearize.
It also sets up name scoping so that the resultant graph is easy to read,
and adds a number of summary ops.
"""
# Adding a name scope ensures logical grouping of the layers in the graph.
with tf.name_scope(layer_name):
# This Variable will hold the state of the weights for the layer
with tf.name_scope('weights'):
weights = weight_variable([input_dim, output_dim])
variable_summaries(weights)
with tf.name_scope('biases'):
biases = bias_variable([output_dim])
variable_summaries(biases)
with tf.name_scope('Wx_plus_b'):
preactivate = tf.matmul(input_tensor, weights) + biases
tf.summary.histogram('pre_activations', preactivate)
activations = act(preactivate, name='activation')
tf.summary.histogram('activations', activations)
return activations
hidden1 = nn_layer(x, 784, 500, 'layer1')
with tf.name_scope('dropout'):
keep_prob = tf.placeholder(tf.float32)
tf.summary.scalar('dropout_keep_probability', keep_prob)
dropped = tf.nn.dropout(hidden1, keep_prob)
# Do not apply softmax activation yet, see below.
y = nn_layer(dropped, 500, 10, 'layer2', act=tf.identity)
with tf.name_scope('cross_entropy'):
# The raw formulation of cross-entropy,
#
# tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(tf.softmax(y)),
# reduction_indices=[1]))
#
# can be numerically unstable.
#
# So here we use tf.nn.softmax_cross_entropy_with_logits on the
# raw outputs of the nn_layer above, and then average across
# the batch.
diff = tf.nn.softmax_cross_entropy_with_logits(targets=y_, logits=y)
with tf.name_scope('total'):
cross_entropy = tf.reduce_mean(diff)
tf.summary.scalar('cross_entropy', cross_entropy)
with tf.name_scope('train'):
train_step = tf.train.AdamOptimizer(FLAGS.learning_rate).minimize(
cross_entropy)
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
# Merge all the summaries and write them out to /tmp/mnist_logs (by default)
merged = tf.summary.merge_all()
train_writer = tf.summary.FileWriter(FLAGS.summaries_dir + '/train',
sess.graph)
test_writer = tf.summary.FileWriter(FLAGS.summaries_dir + '/test')
tf.global_variables_initializer().run()FileWriter를 초기화 한 후에는 모델을 테스트하고 테스트 할 때 FileWriter에 요약을 추가해야합니다.
# Train the model, and also write summaries.
# Every 10th step, measure test-set accuracy, and write test summaries
# All other steps, run train_step on training data, & add training summaries
def feed_dict(train):
"""Make a TensorFlow feed_dict: maps data onto Tensor placeholders."""
if train or FLAGS.fake_data:
xs, ys = mnist.train.next_batch(100, fake_data=FLAGS.fake_data)
k = FLAGS.dropout
else:
xs, ys = mnist.test.images, mnist.test.labels
k = 1.0
return {x: xs, y_: ys, keep_prob: k}
for i in range(FLAGS.max_steps):
if i % 10 == 0: # Record summaries and test-set accuracy
summary, acc = sess.run([merged, accuracy], feed_dict=feed_dict(False))
test_writer.add_summary(summary, i)
print('Accuracy at step %s: %s' % (i, acc))
else: # Record train set summaries, and train
summary, _ = sess.run([merged, train_step], feed_dict=feed_dict(True))
train_writer.add_summary(summary, i)이제 TensorBoard를 사용하여이 데이터를 시각화 할 수 있습니다.
Launching TensorBoard
TensorBoard 출시
TensorBoard를 실행하려면 다음 명령을 사용하십시오 (또는 python -m tensorboard.main).
tensorboard --logdir=path/to/log-directory여기서 logdir은 FileWriter가 데이터를 직렬화 한 디렉토리를 가리 킵니다. 이 logdir 디렉토리에 별도의 실행에서 직렬화 된 데이터가 들어있는 하위 디렉토리가 있으면 TensorBoard는 이러한 모든 실행에서 데이터를 시각화합니다. TensorBoard가 실행되면 웹 브라우저에서 localhost : 6006으로 이동하여 TensorBoard를 봅니다.
TensorBoard를 보면 오른쪽 상단 모서리에 탐색 탭이 표시됩니다. 각 탭은 시각화 할 수있는 직렬화 된 데이터 집합을 나타냅니다.
그래프 탭을 사용하여 그래프를 시각화하는 방법에 대한 자세한 내용은 TensorBoard : 그래프 시각화를 참조하십시오.
TensorBoard에 대한 자세한 사용 정보는 TensorBoard의 GitHub(TensorBoard's GitHub)를 참조하십시오.
'Computer_IT > tensorflow' 카테고리의 다른 글
| tf.estimator로 입력 함수 작성하기 (0) | 2017.11.24 |
|---|---|
| [텐서플로우] CSV 활용하기/ 간단한 판별 AI 만들기 (0) | 2017.10.10 |
| TensorFlow Mechanics 101 (0) | 2017.08.24 |
| Deep MNIST for Experts ( 히든 레이어 버전) (0) | 2017.06.30 |
| [인공지능] Tensorflow 프로그래머 가이드부터 다시 시작하자. (0) | 2017.06.22 |
tf.estimator로 입력 함수 작성하기
Building Input Functions with tf.estimator
import numpy as np
training_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=IRIS_TRAINING, target_dtype=np.int, features_dtype=np.float32)
train_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"x": np.array(training_set.data)},
y=np.array(training_set.target),
num_epochs=None,
shuffle=True)
classifier.train(input_fn=train_input_fn, steps=2000)input_fn의 해부 다음 코드는 입력 함수의 기본 골격을 보여줍니다.
def my_input_fn():
# Preprocess your data here...
# ...then return 1) a mapping of feature columns to Tensors with
# the corresponding feature data, and 2) a Tensor containing labels
return feature_cols, labels입력 함수의 본문에는 잘못된 예제를 스크러빙하거나 피쳐 스케일링과 같이 입력 데이터를 사전 처리하는 특정 논리가 포함되어 있습니다.
입력 함수는 위의 코드 스켈레톤에서와 같이 모델에 공급할 최종 피처 및 레이블 데이터가 포함 된 다음 두 값을 반환해야합니다.
feature_cols
피쳐 열 이름을 해당 피처 데이터가 들어있는 Tensors (또는 SparseTensors)에 매핑하는 키 / 값 쌍을 포함하는 사전입니다.
labels
라벨 (목표) 값을 포함하는 Tensor : 모델이 예측하고자하는 값.
피쳐 데이터를 텐서 (tensors)로 변환
feature / label 데이터가 python 배열이거나 pandas 데이터 프레임 또는 numpy 배열에 저장되어있는 경우 다음 메소드를 사용하여 input_fn을 생성 할 수 있습니다.
import numpy as np
# numpy input_fn.
my_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"x": np.array(x_data)},
y=np.array(y_data),
...)
import pandas as pd
# pandas input_fn.
my_input_fn = tf.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({"x": x_data}),
y=pd.Series(y_data),
...)스파스 데이터(대부분의 값이 0인 데이터)의 경우, 세개의 인수로 인스턴스화된 SparseTensor를 채우는 대신 SparseTensor를 채웁니다.
dense_shape
텐서의 모양. 각 차원의 요소 수를 나타내는 목록을 가져옵니다. 예를 들어 dense_shape = [3,6]은 2 차원 3x6 텐서를 지정하고 dense_shape = [2,3,4]는 3 차원 2x3x4 텐서를 지정하고 dense_shape = [9]는 9 개 요소가있는 1 차원 텐서를 지정합니다. .
indices
0이 아닌 값을 포함하는 텐서 요소의 인덱스입니다. 용어 목록을 취합니다. 여기서 각 용어는 자체가 0이 아닌 요소의 색인을 포함하는 목록입니다. 요소는 0으로 인덱싱됩니다. 즉, [0,0]은 2 차원 텐서에서 첫 번째 행의 첫 번째 열에있는 요소의 인덱스 값입니다. 예 : indices = [[1,3], [ 2,4]]는 [1,3]과 [2,4]의 인덱스가 0이 아닌 값을 갖도록 지정합니다.
values
1 차원 값의 텐서. 값의 항 i은 인덱스의 항 i에 해당하며 해당 값을 지정합니다. 예를 들어, 주어진 indices = [[1,3], [2,4]]에서, 매개 변수 값 = [18, 3.6]은 텐서의 원소 [1,3]가 18의 값을 갖고, [2 , 4]의 값은 3.6입니다.
다음 코드는 3 행 5 열의 2 차원 SparseTensor를 정의합니다. 인덱스가 [0,1] 인 요소의 값은 6이고 인덱스 [2,4]가있는 요소의 값은 0.5입니다 (다른 모든 값은 0입니다).
sparse_tensor = tf.SparseTensor(indices=[[0,1], [2,4]],
values=[6, 0.5],
dense_shape=[3, 5])이것은 다음과 같은 밀도가 높은 텐서에 해당합니다.
[[0, 6, 0, 0, 0]
[0, 0, 0, 0, 0]
[0, 0, 0, 0, 0.5]]SparseTensor에 대한 자세한 내용은 tf.SparseTensor를 참조하십시오.
모델에 input_fn 데이터 전달
훈련을 위해 모델에 데이터를 공급하려면 입력 작업 기능에 입력 기능을 input_fn 매개 변수의 값으로 전달하기 만하면됩니다.
classifier.train(input_fn=my_input_fn, steps=2000)input_fn 매개 변수는 함수 호출 (input_fn = my_input_fn ())의 반환 값이 아닌 함수 객체 (예 : input_fn = my_input_fn)를 수신해야합니다. 즉, 기차 코드에서 input_fn에 매개 변수를 전달하려고하면 다음 코드와 같이 TypeError가 발생합니다.
classifier.train(input_fn=my_input_fn(training_set), steps=2000)그러나 입력 함수를 매개 변수화 할 수 있기를 원하면 다른 방법이 있습니다. 인수를 취하지 않고 input_fn과 같은 래퍼 함수를 사용하여 원하는 매개 변수로 입력 함수를 호출 할 수 있습니다. 예제소스:
def my_input_fn(data_set):
...
def my_input_fn_training_set():
return my_input_fn(training_set)
classifier.train(input_fn=my_input_fn_training_set, steps=2000)또는 파이썬의 functools.partial 함수를 사용하여 모든 매개 변수 값이 고정 된 새 함수 객체를 생성 할 수 있습니다.
classifier.train(
input_fn=functools.partial(my_input_fn, data_set=training_set),
steps=2000)세 번째 옵션은 input_fn 호출을 람다에 랩핑하여 input_fn 매개 변수에 전달하는 것입니다.
classifier.train(input_fn=lambda: my_input_fn(training_set), steps=2000)위에 표시된 입력 파이프 라인을 설계하여 데이터 세트에 대한 매개 변수를 허용하는 한 가지 큰 장점은 데이터 세트 인수 만 변경하여 동일한 input_fn을 전달하여 연산을 평가하고 예측할 수 있다는 것입니다 (예 :
classifier.evaluate(input_fn=lambda: my_input_fn(test_set), steps=2000)이 접근법은 코드 유지 보수성을 향상시킵니다. 각 유형의 작업에 대해 여러 input_fn (예 : input_fn_train, input_fn_test, input_fn_predict)을 정의 할 필요가 없습니다.
마지막으로, tf.estimator.inputs의 메소드를 사용하여 numpy 또는 pandas 데이터 세트에서 input_fn을 작성할 수 있습니다. 추가적인 이점은 num_epochs 및 shuffle과 같은 인수를 사용하여 input_fn이 데이터를 반복하는 방식을 제어 할 수 있다는 것입니다.
import pandas as pd
def get_input_fn_from_pandas(data_set, num_epochs=None, shuffle=True):
return tf.estimator.inputs.pandas_input_fn(
x=pdDataFrame(...),
y=pd.Series(...),
num_epochs=num_epochs,
shuffle=shuffle)
import numpy as np
def get_input_fn_from_numpy(data_set, num_epochs=None, shuffle=True):
return tf.estimator.inputs.numpy_input_fn(
x={...},
y=np.array(...),
num_epochs=num_epochs,
shuffle=shuffle)보스턴 하우스 가치를위한 신경망 모델
이 튜토리얼의 나머지 부분에서는 UCI 주택 데이터 세트에서 가져온 Boston 주택 데이터의 하위 집합을 사전 처리하기위한 입력 함수를 작성하고 중앙 집 값을 예측하기 위해 신경 네트워크 회귀 분석기로 데이터를 공급하는 데이 함수를 사용합니다.
신경망을 훈련하는 데 사용할 보스턴 CSV 데이터 세트(Boston CSV data sets)는 Boston 교외 지역에 대한 다음과 같은 기능 데이터를 포함합니다.
| Feature | Description |
|---|---|
| CRIM | Crime rate per capita / 1 인당 범죄율 |
| ZN | Fraction of residential land zoned to permit 25,000+ sq ft lots / 25,000+ 평방 피트를 허용하도록 구역화 된 주거용 토지의 분수 |
| INDUS | Fraction of land that is non-retail business / 비 소매업 부문 토지의 비율 |
| NOX | Concentration of nitric oxides in parts per 10 million / 질소 산화물의 농도를 천만 배럴로 |
| RM | Average Rooms per dwelling / 주거 당 RM 평균 객실 |
| AGE | Fraction of owner-occupied residences built before 1940 / 1940 년 이전에 건축 된 주거지의 일부 |
| DIS | Distance to Boston-area employment centers / 보스턴 지역 고용 센터까지의 거리 |
| TAX | Property tax rate per $10,000 / 10,000 달러 당 세율 |
| PTRATIO | Student-teacher ratio / 교사 비율 |
그리고 모델에서 예측할 수있는 레이블은 수천 달러의 소유자가 거주하는 주택의 중간 값 인 MEDV입니다.
설정
boston_train.csv, boston_test.csv 및 boston_predict.csv 데이터 세트를 다운로드하십시오.( boston_train.csv, boston_test.csv, and boston_predict.csv.)
다음 섹션에서는 입력 함수를 작성하고 이러한 데이터 세트를 신경망 회귀 분석기에 공급하고 모델을 학습 및 평가하며 주택 가치 예측을 수행하는 방법을 단계별로 설명합니다. 완전한 최종 코드가 여기(available here)에 있습니다.
주택 데이터 가져 오기
시작하려면 가져 오기 (팬더 및 텐서 흐름 포함)를 설정하고 자세한 로그 출력을 위해 자세한 정보 표시를 INFO로 설정하십시오.
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import itertools
import pandas as pd
import tensorflow as tf
tf.logging.set_verbosity(tf.logging.INFO)COLUMNS에있는 데이터 세트의 열 이름을 정의하십시오. 레이블과 기능을 구별하려면 FEATURES 및 LABEL도 정의하십시오. 그런 다음 3 개의 CSV (tf.train, tf.test 및 예측)를 판다 데이터 프레임으로 읽습니다.
COLUMNS = ["crim", "zn", "indus", "nox", "rm", "age",
"dis", "tax", "ptratio", "medv"]
FEATURES = ["crim", "zn", "indus", "nox", "rm",
"age", "dis", "tax", "ptratio"]
LABEL = "medv"
training_set = pd.read_csv("boston_train.csv", skipinitialspace=True,
skiprows=1, names=COLUMNS)
test_set = pd.read_csv("boston_test.csv", skipinitialspace=True,
skiprows=1, names=COLUMNS)
prediction_set = pd.read_csv("boston_predict.csv", skipinitialspace=True,
skiprows=1, names=COLUMNS)FeatureColumns 정의 및 회귀 변수 만들기
그런 다음 입력 데이터에 대한 FeatureColumns 목록을 작성하십시오.이 목록은 공식적으로 교육에 사용할 피처 세트를 지정합니다. 주택 데이터 세트의 모든 피쳐에는 연속 값이 포함되어 있으므로 tf.contrib.layers.real_valued_column () 함수를 사용하여 FeatureColumns를 작성할 수 있습니다.
feature_cols = [tf.feature_column.numeric_column(k) for k in FEATURES]참고 : 기능 열에 대한 자세한 내용은이 소개를 참조하고 범주 데이터에 대한 FeatureColumns 정의 방법을 보여주는 예제는 선형 모델 자습서를 참조하십시오.
이제 신경망 회귀 모델에 대한 DNNRegressor를 인스턴스화합니다. hidden_units, 각 숨겨진 레이어의 노드 수를 지정하는 하이퍼 매개 변수 (여기서 10 개의 노드가있는 두 개의 숨겨진 레이어) 및 방금 정의한 FeatureColumns 목록이 포함 된 feature_columns를 두 가지 인수로 제공해야합니다.
regressor = tf.estimator.DNNRegressor(feature_columns=feature_cols,
hidden_units=[10, 10],
model_dir="/tmp/boston_model")input_fn 빌드하기
회귀 변수에 입력 데이터를 전달하려면 pandas Dataframe을 허용하고 input_fn을 반환하는 팩터 리 메서드를 작성합니다.
def get_input_fn(data_set, num_epochs=None, shuffle=True):
return tf.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({k: data_set[k].values for k in FEATURES}),
y = pd.Series(data_set[LABEL].values),
num_epochs=num_epochs,
shuffle=shuffle)입력 데이터는 data_set 인수에서 input_fn으로 전달됩니다. 즉, 함수는 training_set, test_set 및 prediction_set과 같이 가져온 DataFrames를 처리 할 수 있습니다.
두 개의 추가 인수가 제공됩니다. num_epochs : 데이터를 반복 할 에포크 수를 제어합니다. 교육의 경우이 값을 없음으로 설정하면
input_fn은 필요한 수의 열차 단계에 도달 할 때까지 데이터를 반환합니다. 평가하고 예측하려면 1로 설정하면 input_fn이 데이터를 한 번 반복 한 다음 OutOfRangeError를 발생시킵니다. 이 오류는 평가자가 평가 또는 예측을 중지하도록 신호를 보냅니다. shuffle : 데이터 셔플 여부. 평가하고 예측하기 위해 이것을 false로 설정하면 input_fn이 데이터를 순차적으로 반복합니다. 열차의 경우이 값을 True로 설정하십시오.
회귀 자 훈련
뉴럴 네트워크 회귀 분석기를 훈련 시키려면 다음과 같이 input_fn에 전달 된 training_set을 사용하여 train을 실행하십시오.
regressor.train(input_fn=get_input_fn(training_set), steps=5000)You should see log output similar to the following, which reports training loss for every 100 steps:
INFO:tensorflow:Step 1: loss = 483.179
INFO:tensorflow:Step 101: loss = 81.2072
INFO:tensorflow:Step 201: loss = 72.4354
...
INFO:tensorflow:Step 1801: loss = 33.4454
INFO:tensorflow:Step 1901: loss = 32.3397
INFO:tensorflow:Step 2001: loss = 32.0053
INFO:tensorflow:Step 4801: loss = 27.2791
INFO:tensorflow:Step 4901: loss = 27.2251
INFO:tensorflow:Saving checkpoints for 5000 into /tmp/boston_model/model.ckpt.
INFO:tensorflow:Loss for final step: 27.1674.모델 평가
다음으로, 훈련 된 모델이 테스트 데이터 세트에 대해 어떻게 수행되는지보십시오. evaluate을 실행하고, 이번에는 test_set을 input_fn으로 전달합니다.
ev = regressor.evaluate(
input_fn=get_input_fn(test_set, num_epochs=1, shuffle=False))
결과를 가져온 결과에서 손실을 검색하고 출력을 출력합니다.
loss_score = ev["loss"]
print("Loss: {0:f}".format(loss_score))
결과는 다음과 유사해야합니다.
INFO:tensorflow:Eval steps [0,1) for training step 5000.
INFO:tensorflow:Saving evaluation summary for 5000 step: loss = 11.9221
Loss: 11.922098예측하기
마지막으로이 모델을 사용하여 feature_data를 포함하고 있지만 6 개의 예제에 대한 레이블이없는 prediction_set의 집값 중앙값을 예측할 수 있습니다.
y = regressor.predict(
input_fn=get_input_fn(prediction_set, num_epochs=1, shuffle=False))
# .predict() returns an iterator of dicts; convert to a list and print
# predictions
predictions = list(p["predictions"] for p in itertools.islice(y, 6))
print("Predictions: {}".format(str(predictions)))
결과에는 6 가지 주택 가치 예측치가 수천 달러로 포함되어야합니다. 예 :
Predictions: [ 33.30348587 17.04452896 22.56370163 34.74345398 14.55953979
19.58005714]'Computer_IT > tensorflow' 카테고리의 다른 글
| [텐서플로우]인공지능 들여다보기(그래프 보기)Tensorboard) (0) | 2017.12.08 |
|---|---|
| [텐서플로우] CSV 활용하기/ 간단한 판별 AI 만들기 (0) | 2017.10.10 |
| TensorFlow Mechanics 101 (0) | 2017.08.24 |
| Deep MNIST for Experts ( 히든 레이어 버전) (0) | 2017.06.30 |
| [인공지능] Tensorflow 프로그래머 가이드부터 다시 시작하자. (0) | 2017.06.22 |
가트너 2018 기술 동향 TOP 10
GartnerTop10전략 기술 동향 10위
인공 지능, 생동감 넘치는 체험, 디지털 쌍둥이, 이벤트, 지속적인 적응형 보안이 차세대 디지털 비즈니스 모델과 에코 시스템을 위한 토대를 마련합니다.
디자이너들은 어떻게 자동차를 더 안전하게 만드는가? 그들은 그들을 마치 물고기처럼 취급한다. 최근 혼다가 발표한 세이프 스웨이는 차량들이 근처의 다른 차들에게 정보를 전달할 수 있도록 차량 대 차량 통신을 이용한다. 예를 들어, 도로 위의 사고 수마일에 대한 경고는 교통 사고를 방지하고 교통을 완화하기 위해 지능적이고 지능적으로 작동할 수 있게 해 줄 수 있다.
집단 사고와 같은 지능적인 것들의 진화와 같은 지능적인 것들은 광범위한 산업적 영향력과 상당한 잠재력의 잠재력을 가진 10가지 전략적 경향들 중 하나이다.
"지속적인 디지털 비즈니스 발전은 직원, 파트너 및 고객을 위한 새로운 디지털 모델을 더욱 긴밀하게 조화시키고 있습니다."라고 Gartner의 올랜도 시에 있는 Gartner2017Symposium부사장 겸 Gartner동료 DavidCearley씨가 말했습니다. "기술은 미래의 디지털 비즈니스에 모든 것에 포함될 것입니다."
인텔리전트 디지털 메쉬
Gartner는 지능형 디지털 메시를 사용하는 사람, 장치, 콘텐츠 및 서비스의 네트워크를 호출합니다. 디지털 비즈니스를 지원하기 위해 디지털 모델, 비즈니스 플랫폼 및 풍부한 지능형 서비스 셋을 사용할 수 있습니다.
지능형:AI가 실질적으로 거의 모든 기술을 갖추고 있고, 잘 정의된 초점을 맞출 수 있는 방법은 보다 동적이고 유연하며 잠재적으로 자율적인 시스템을 구현할 수 있습니다.
디지털:가상 및 실제 환경을 확대하여 생동감 넘치는 디지털 및 연결 환경을 구축합니다.
확대:디지털 결과를 전달하기 위해 확장되는 인력, 사업체, 장치, 콘텐츠 및 서비스 간의 연결.

Intelligent
Trend No. 1: AI Foundation
(AI 인공지능 기반)
의사 결정을 강화하고, 비즈니스 모델과 생태계를 재창조하고, 고객 만족도를 높이기 위해 AI를 사용하는 능력은 2025년까지 디지털 이니셔티브를 추진할 것이다.끊임없이 증가하는 문의 사항의 증가를 감안할 때, 이자율이 증가하고 있다는 것은 분명하다. 최근 Gartner설문 조사에 따르면 조직의 59%가 AI전략을 구축하고 있으며, 나머지는 이미 지능형 솔루션을 구축하거나 채택하는 과정에서 진전을 이루고 있는 것으로 나타났습니다.
비록 인공 지능을 바르게 사용하는 것은 인간이 할 수 있는 모든 지능적인 임무를 수행하고 인간이 하는 것만큼 동적으로 학습할 수 있는 지능적인 임무를 수행한다. 이 과제에 최적화된 알고리즘을 사용하여 특정 작업을 수행하거나 제어 환경에서 차량을 구동하는 것과 같은 특정한 작업(예:언어를 이해하거나 제어하는 것)으로 구성된 매우 정밀한 기계 학습 솔루션입니다. "기업들은 편협한 AI기술을 이용한 응용 프로그램에 의해 지원되는 응용 프로그램에 집중하고 일반적인 AI를 연구자들과 공상 과학 작가들에게 맡겨야 합니다."라고 Celeley는 말합니다.
Trend No. 2: Intelligent Apps and Analytics
지능형 애플리케이션 및 분석
향후 몇년간 모든 애플리케이션, 애플리케이션 및 서비스는 어느 수준에서나 AI를 통합할 것입니다. AI는 완전히 새로운 응용 분야를 배경으로 하는 어플리케이션들의 배경에서 볼 수 없을 정도로 무의식적으로 운영될 것이다. AI는 ERP의 측면을 포함한 광범위한 소프트웨어 및 서비스 시장에서 차세대 경쟁 구도가 되었다. "패키지 소프트웨어 및 서비스 공급 업체에 도전하여 지능형 분석, 지능형 프로세스 및 고급 사용자 환경에서 새로운 버전의 비즈니스 가치를 창출할 수 있는 방법을 소개합니다."라고 Cearley는 말합니다.
지능형 애플리케이션은 또한 사람과 시스템 간의 새로운 지능형 중간 계층을 만들어 내고, 가상 고객 보조 및 기업 컨설턴트 및 보조원과 같이 업무의 특성과 작업 공간을 혁신할 수 있습니다.
"지능형 애플리케이션을 사람들을 대체하는 방식으로 단순화하는 방법으로 지능적인 애플리케이션을 탐색하는 방법은 아닙니다."라고 Cearley는 말합니다. 증강 분석은 특히 광범위한 비즈니스 사용자, 운영자 및 시민 데이터 과학자에게 데이터 준비, 통찰력 및 통찰력을 제공하는 기계 학습을 자동화하는 데 사용되는 전략적 성장 영역입니다.
Trend No. 3: Intelligent Things
클라우드로의 클라우드 전환
Edge컴퓨팅은 정보 처리 및 컨텐츠 수집 및 전송이 이 정보의 소스에 더 가깝게 배치되는 컴퓨팅 토폴로지를 설명합니다. 연결 및 지연 시간 문제, 대역 폭 제약 및 에지에 포함된 더 큰 기능은 분산 모델을 선호합니다. 기업은 특히 중요한 IoT요소를 갖춘 인프라 스트럭처 아키텍처에서 인프라 스트럭처 설계 패턴을 사용하기 시작해야 합니다. 좋은 시작 지점은 코로 케이션 및 특정 네트워크 관련 네트워킹 기능을 사용할 수 있습니다.
클라우드와 에지 컴퓨팅이 경쟁적인 접근법이라고 가정하는 것은 일반적으로 개념에 대한 근본적인 오해입니다. Edge컴퓨팅은 컨텐츠, 컴퓨팅 및 프로세싱을 사용하여 네트워킹의 사용자 인터페이스 또는"에지"에 대한 보다 자세한 정보를 제공하는 컴퓨팅 토폴로지를 말합니다. 클라우드는 기술 서비스를 이용하여 기술 서비스를 제공하는 시스템이지만, 서비스를 제공하는 서비스를 제공하는 서비스를 제공하지 않습니다. 함께 구현될 때 클라우드 서비스는 서비스 지향 모델을 생성하는 데 사용되며, 클라우드 서비스는 연결되지 않은 클라우드 서비스를 실행할 수 있는 제공 방식을 제공합니다.
Trend No. 6: Conversational Platforms
대화형 플랫폼
대화형 플랫폼은 사용자가 컴퓨터에서 컴퓨터로 전환하는 번거로움을 일으키는 패러다임의 변화를 주도하게 됩니다. 이러한 시스템들은 간단한 답변을 할 수 있다. 대화형 플랫폼이 직면한 과제는 사용자가 매우 체계적인 방식으로 소통해야 한다는 점입니다. 이는 종종 실망스러운 경험입니다. 대화형 플랫폼의 주된 차별화 요소는 복잡한 결과를 전달하기 위해 타사 서비스에 액세스하고 사용하는 데 사용되는 대화형 모델과 API및 이벤트 모델의 견고함과 동기화입니다.
Trend No. 7: Immersive Experience
즉흥적 경험
증강 현실(AR), 가상 현실(VR)및 혼합 현실은 사람들이 디지털 세상을 인식하고 소통하는 방식을 바꾸고 있습니다. 대화형 플랫폼과 결합하여 사용자 경험이 보이지 않는 환경에서 사용자 환경의 근본적인 변화가 나타날 것입니다. 애플리케이션 벤더, 시스템 소프트웨어 공급 업체 및 개발 플랫폼 벤더가 이 모델을 제공하기 위해 경쟁합니다.
향후 5년 동안 사용자는 물리적 환경을 유지하면서 디지털 및 실제 객체와 상호 작용하는 생동감 있는 경험으로 부각되는 복합적인 현실에 초점을 맞추게 됩니다. 혼합된 현실은 스펙트럼을 따라 존재하며, AR이나 VR기반 AR뿐만 아니라 AR또는 태블릿 기반 AR에 대한 Head-mounted(HMD)를 포함합니다. 모바일 기기와 애플의 아이 폰 엑스, 구글의 탱고, 구글과 같은 크로스 플랫폼 소프트웨어 개발 키트의 유용성을 감안할 때, 우리는 스마트 폰 기반 AR소프트웨어 개발 키트와 스마트 폰 기반 AR을 2018년에 가열할 것으로 기대합니다.
Mesh
Trend No. 8: Blockchain블록
Blockahain은 개별 애플리케이션이나 참가자와는 무관하게 비즈니스 마찰을 배제하는 분산형 분산형 분산형 분산형 계정입니다. 그것은 신뢰할 수 없는 당사자들이 상업 거래를 교환할 수 있게 해 준다. 이 기술은 산업을 변화시킬 약속을 하고 있지만, 대화는 종종 재정적 기회를 수반하지만, 블록는 정부, 의료, 콘텐츠 유통, 공급망 등에 많은 잠재적인 애플리케이션을 가지고 있다. 하지만, 많은 블로슈차인 기술은 미숙하고 검증되지 않았고 대체로 규제되지 않았다.
blockshan에 대한 실용적인 접근법은 비즈니스 기회, 즉 Blockshain, Trust아키텍처의 능력, 신뢰 아키텍처 및 필요한 구현 기술에 대한 명확한 이해를 요구합니다. 디스트리뷰터가 배포된 프로젝트를 시작하기 전에 팀의 암호화 기술이 무엇인지 이해할 수 있도록 암호화 기술을 보유하고 있어야 합니다. 기존 인프라 스트럭처와의 통합 지점을 식별하고 플랫폼의 진화 및 성숙도를 모니터링합니다. 벤더와 상호 작용할 때 극도로 주의를 기울이고,"블록차"라는 용어를 사용하는 방법을 명확하게 식별합니다.
Trend No. 9: Event-Driven
EVENT
디지털 비즈니스는 새로운 디지털 비즈니스를 활용할 수 있는 능력에 의존하고 있습니다. 비즈니스 이벤트는 구매 주문 작성과 같은 중요한 상태 또는 주 변경 사항의 발견을 반영합니다. 일부 비즈니스 이벤트 또는 이벤트 조합은 비즈니스의 몇가지 특정 비즈니스 활동을 요구하는 탐지된 상황을 구성합니다. 가장 중요한 비즈니스 순간은 개별 애플리케이션, LOB(LineofBusiness)또는 파트너와 같은 여러 당사자에게 영향을 미치는 것입니다.
AI, IoT및 기타 기술의 출현으로 비즈니스 이벤트가 보다 신속하게 보다 신속하게 파악되고 분석될 수 있습니다. 기업들은 디지털 비즈니스 전략의 일환으로 "이벤트 사고"를 받아들여야 합니다. 2020년까지, 전자 상거래의 실시간 상황 인식은 디지털 비즈니스 솔루션의 80%에 필수적인 특성이 될 것이며, 새로운 비즈니스 생태계의 80%는 이벤트 처리를 위한 지원이 필요할 것이다.
Trend No. 10: Continuous Adaptive Risk and Trust
지속적인 AdaptiveRisk및 신뢰성
디지털 비즈니스는 복잡하고 진화하는 보안 환경을 조성합니다. 점점 더 정교해 지는 도구를 사용하면 위협 잠재력이 높아집니다. 연속적인 AdaptiveRisk및 신뢰성 평가(CARTA)는 보안 가능한 디지털 비즈니스에 대한 적응형 대응으로 실시간, 위험 및 신뢰성 기반 의사 결정을 지원합니다. 신뢰보다는 소유권과 통제를 사용하는 전통적인 보안 기법은 디지털 세상에서 작동하지 않습니다. 인프라 스트럭처 및 주변 보호 기능은 정확한 감지를 보장하지 않으며, 따라서 내부의 내부자 공격으로부터 보호할 수 없습니다. 이를 통해 보안 중심의 보안을 수용하고 보안 조치에 대한 책임을 지도록 개발자에게 권한을 부여할 필요가 있습니다. DevOps를 활용하여"DevOOps"프로세스를 구축하고, 네트워크에 침투한 악의적인 기술(예:적응형 가정용)을 탐색하기 위해 보안 기술을 개발하는 것은 CARTA를 현실화하는 새로운 기술입니다.
'정보' 카테고리의 다른 글
| 삼성 U-Flex 구매 및 사용 후기 (0) | 2017.11.17 |
|---|---|
| 포천 시외버스 터미널 시간표 17.11.01 (1) | 2017.11.01 |
| [아이디어] Heng Lamp / 밸런스 스탠드 (0) | 2017.09.08 |
| 연수기란?? (0) | 2017.08.18 |
| [펌] 한눈에 살펴보는 PostgreSQL (0) | 2017.06.13 |
[텐서플로우] CSV 활용하기/ 간단한 판별 AI 만들기
TensorFlow의 고급 기계 학습 API (tf.estimator)를 사용하면 다양한 기계 학습 모델을 쉽게 구성, 교육 및 평가할 수 있습니다. 이 튜토리얼에서는 tf.estimator를 사용하여 신경 네트워크 분류기를 만들고 Iris 데이터 세트
(Iris data set )에서이를 학습하여 sepal / petal geometry를 기반으로 꽃 종을 예측합니다. 다음 다섯 단계를 수행하는 코드를 작성합니다.
1.Iris 교육 / 테스트 데이터가 포함 된 CSV를 TensorFlow Dataset에로드하십시오.
2.신경 네트워크 분류 자 생성
3.교육 데이터를 사용하여 모델 교육
4.모델의 정확성 평가
5.새 샘플 분류
참고 :이 자습서를 시작하기 전에 TensorFlow를 컴퓨터에 설치해야합니다.
Complete Neural Network Source Code(완전한 신경 네트워크 소스 코드)
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import urllib
import numpy as np
import tensorflow as tf
# Data sets
IRIS_TRAINING = "iris_training.csv"
IRIS_TRAINING_URL = "http://download.tensorflow.org/data/iris_training.csv"
IRIS_TEST = "iris_test.csv"
IRIS_TEST_URL = "http://download.tensorflow.org/data/iris_test.csv"
def main():
# If the training and test sets aren't stored locally, download them.
if not os.path.exists(IRIS_TRAINING):
raw = urllib.urlopen(IRIS_TRAINING_URL).read()
with open(IRIS_TRAINING, "w") as f:
f.write(raw)
if not os.path.exists(IRIS_TEST):
raw = urllib.urlopen(IRIS_TEST_URL).read()
with open(IRIS_TEST, "w") as f:
f.write(raw)
# Load datasets.
training_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=IRIS_TRAINING,
target_dtype=np.int,
features_dtype=np.float32)
test_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=IRIS_TEST,
target_dtype=np.int,
features_dtype=np.float32)
# Specify that all features have real-value data
feature_columns = [tf.feature_column.numeric_column("x", shape=[4])]
# Build 3 layer DNN with 10, 20, 10 units respectively.
classifier = tf.estimator.DNNClassifier(feature_columns=feature_columns,
hidden_units=[10, 20, 10],
n_classes=3,
model_dir="/tmp/iris_model")
# Define the training inputs
train_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"x": np.array(training_set.data)},
y=np.array(training_set.target),
num_epochs=None,
shuffle=True)
# Train model.
classifier.train(input_fn=train_input_fn, steps=2000)
# Define the test inputs
test_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"x": np.array(test_set.data)},
y=np.array(test_set.target),
num_epochs=1,
shuffle=False)
# Evaluate accuracy.
accuracy_score = classifier.evaluate(input_fn=test_input_fn)["accuracy"]
print("\nTest Accuracy: {0:f}\n".format(accuracy_score))
# Classify two new flower samples.
new_samples = np.array(
[[6.4, 3.2, 4.5, 1.5],
[5.8, 3.1, 5.0, 1.7]], dtype=np.float32)
predict_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"x": new_samples},
num_epochs=1,
shuffle=False)
predictions = list(classifier.predict(input_fn=predict_input_fn))
predicted_classes = [p["classes"] for p in predictions]
print(
"New Samples, Class Predictions: {}\n"
.format(predicted_classes))
if __name__ == "__main__":
main()다음 섹션에서는 코드를 자세히 설명합니다.
Load the Iris CSV data to TensorFlow / Iris CSV데이터를 TensorFlow에 로드.
Iris 데이터 세트에는 Iris setosa, Iris virginica 및 Iris versicolor와 같은 세 가지 관련된 Iris 종 각각에서 추출한 50 개의 샘플로 구성된 150 행의 데이터가 들어 있습니다.

왼쪽에서 오른쪽으로 Iris setosa (Radomil, CC BY-SA 3.0), Iris versicolor (Dlanglois, CC BY-SA 3.0), Iris virginica (Frank Mayfield, CC BY-SA 2.0) 입니다.
각 행은 각 꽃 샘플에 대한 다음 데이터를 포함합니다 : 꽃잎 길이, 꽃잎 너비, 꽃잎 길이, 꽃잎 너비 및 꽃 종. 꽃 종은 정수로 표시되며, 0은 아이리스 세토 사, 1은 아이리스 versicolor, 2는 아이리스 virginica를 나타냅니다.
| Sepal Length | Sepal Width | Petal Length | Petal Width | Species |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 4.9 | 3.0 | 1.4 | 0.2 | 0 |
| 4.7 | 3.2 | 1.3 | 0.2 | 0 |
| … | … | … | … | … |
| 7.0 | 3.2 | 4.7 | 1.4 | 1 |
| 6.4 | 3.2 | 4.5 | 1.5 | 1 |
| 6.9 | 3.1 | 4.9 | 1.5 | 1 |
| … | … | … | … | … |
| 6.5 | 3.0 | 5.2 | 2.0 | 2 |
| 6.2 | 3.4 | 5.4 | 2.3 | 2 |
| 5.9 | 3.0 | 5.1 | 1.8 | 2 |
이 자습서에서는 아이리스 (Iris) 데이터가 무작위로 분리되어 두 개의 별도 CSV로 나뉩니다.
- A training set of 120 samples (iris_training.csv)
- A test set of 30 samples (iris_test.csv).
시작하려면 먼저 필요한 모든 모듈을 가져오고 데이터 세트를 다운로드하고 저장할 위치를 정의하십시오.
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import urllib
import tensorflow as tf
import numpy as np
IRIS_TRAINING = "iris_training.csv"
IRIS_TRAINING_URL = "http://download.tensorflow.org/data/iris_training.csv"
IRIS_TEST = "iris_test.csv"
IRIS_TEST_URL = "http://download.tensorflow.org/data/iris_test.csv"그런 다음 교육 및 테스트 세트가 로컬에 저장되어 있지 않으면 다운로드하십시오.
if not os.path.exists(IRIS_TRAINING):
raw = urllib.urlopen(IRIS_TRAINING_URL).read()
with open(IRIS_TRAINING,'w') as f:
f.write(raw)
if not os.path.exists(IRIS_TEST):
raw = urllib.urlopen(IRIS_TEST_URL).read()
with open(IRIS_TEST,'w') as f:
f.write(raw)다음으로 learn.datasets.base의 load_csv_with_header () 메소드를 사용하여 교육 및 테스트 세트를 데이터 세트에로드하십시오. load_csv_with_header () 메소드는 세 가지 필수 인수를 취합니다.
filename 파일 경로를 CSV 파일로 가져옵니다.
target_dtype - 데이터 세트의 대상 값에 numpy 데이터 유형을 사용합니다.
features_dtype : 데이터 집합의 특징 값에 numpy 데이터 유형을 사용합니다.
여기에서 목표 (모델을 예측하기 위해 훈련하는 값)는 0-2의 정수로 꽃의 종류이므로 적절한 numpy 데이터 유형은 np.int입니다.
# Load datasets.
training_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=IRIS_TRAINING,
target_dtype=np.int,
features_dtype=np.float32)
test_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=IRIS_TEST,
target_dtype=np.int,
features_dtype=np.float32)tf.contrib.learn의 데이터 세트는 튜플로 명명됩니다. 데이터 및 대상 필드를 통해 기능 데이터 및 대상 값에 액세스 할 수 있습니다. 여기서, training_set.data 및 training_set.target은 각각 학습 세트에 대한 피쳐 데이터 및 목표 값을 포함하고, test_set.data 및 test_set.target은 피쳐 데이터 및 테스트 세트에 대한 목표 값을 포함한다.
나중에 "DNNClassifier를 Iris 교육 데이터에 맞추기"에서 training_set.data 및 training_set.target을 사용하여 모델을 교육하고 "모델 정확성 평가"에서 test_set.data 및 test_set.target을 사용합니다. . 하지만 먼저 다음 섹션에서 모델을 구성 해 보겠습니다.
Construct a Deep Neural Network Classifier
tf.estimator는 Estimator라고하는 미리 정의 된 다양한 모델을 제공하며, "즉시"사용하여 데이터에 대한 교육 및 평가 작업을 실행할 수 있습니다. 여기서, 아이리스 (Iris) 데이터에 맞게 딥 뉴럴 네트워크 분류 자 모델을 구성 할 것입니다. tf.estimator를 사용하면 몇 줄의 코드로 tf.estimator.DNNClassifier를 인스턴스화 할 수 있습니다.
# Specify that all features have real-value data
feature_columns = [tf.feature_column.numeric_column("x", shape=[4])]
# Build 3 layer DNN with 10, 20, 10 units respectively.
classifier = tf.estimator.DNNClassifier(feature_columns=feature_columns,
hidden_units=[10, 20, 10],
n_classes=3,
model_dir="/tmp/iris_model")위의 코드는 데이터 집합의 지형지 물에 대한 데이터 형식을 지정하는 모델의 지형지 물 열을 먼저 정의합니다. 모든 기능 데이터는 연속적이므로 tf.feature_column.numeric_column은 기능 컬럼을 구성하는 데 사용할 수있는 적절한 함수입니다. 데이터 세트에는 세 가지 기능 (세퍼리 폭, 세팔 높이, 꽃잎 너비 및 꽃잎 높이)이 있으므로 모든 데이터를 저장하려면 모양을 [4]로 설정해야합니다.
그런 다음 코드는 다음 인수를 사용하여 DNNClassifier 모델을 만듭니다.
1. feature_columns = feature_columns. 위에 정의 된 기능 열 집합입니다.
2. hidden_units = [10, 20, 10]. 10, 20 및 10 개의 뉴런을 포함하는 3 개의 숨겨진 레이어입니다.
3. n_classes = 3. 3 개의 아이리스 종을 나타내는 3 개의 대상 클래스입니다.
4. model_dir = / tmp / iris_model. 모델 교육 중에 TensorFlow가 검사 점 데이터와 TensorBoard 요약을 저장할 디렉토리입니다.
Describe the training input pipeline
tf.estimator API는 모델의 데이터를 생성하는 TensorFlow 조작을 작성하는 입력 기능을 사용합니다. tf.estimator.inputs.numpy_input_fn을 사용하여 입력 파이프 라인을 생성 할 수 있습니다.
# Define the training inputs
train_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"x": np.array(training_set.data)},
y=np.array(training_set.target),
num_epochs=None,
shuffle=True)Fit the DNNClassifier to the Iris Training Data
이제 DNN 분류기 모델을 구성 했으므로 train 메서드를 사용하여 Iris 교육 데이터에 맞출 수 있습니다. train_input_fn을 input_fn으로 전달하고 훈련 단계 수를 입력하십시오 (here, 2000).
# Train model.
classifier.train(input_fn=train_input_fn, steps=2000)모델의 상태는 분류 기준에 유지되므로 원하는 경우 반복적으로 학습 할 수 있습니다. 예를 들어, 위의 내용은 다음과 같습니다.
classifier.train(input_fn=train_input_fn, steps=1000)
classifier.train(input_fn=train_input_fn, steps=1000)그러나 기차를 타는 동안 모델을 추적하려는 경우 TensorFlow SessionRunHook을 사용하여 로깅 작업을 수행하는 것이 좋습니다.
Evaluate Model Accuracy / 모델 정확도 평가
Iris 교육 데이터에서 DNNClassifier 모델을 교육했습니다. 이제 평가 방법을 사용하여 아이리스 테스트 데이터에서 정확성을 확인할 수 있습니다. train과 마찬가지로 evaluate은 입력 파이프 라인을 만드는 입력 함수를 사용합니다. evaluate은 평가 결과로 dicts를 반환합니다. 다음 코드는 Iris 테스트 data-test_set.data와 test_set.target을 전달하여 결과의 정확성을 평가하고 인쇄합니다.
# Define the test inputs
test_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"x": np.array(test_set.data)},
y=np.array(test_set.target),
num_epochs=1,
shuffle=False)
# Evaluate accuracy.
accuracy_score = classifier.evaluate(input_fn=test_input_fn)["accuracy"]
print("\nTest Accuracy: {0:f}\n".format(accuracy_score))참고 : numpy_input_fn에 대한 num_epochs = 1 인수가 중요합니다. test_input_fn은 데이터를 한 번 반복 한 다음 OutOfRangeError를 발생시킵니다. 이 오류는 분류 작업이 평가를 중단하도록 신호를 보내므로 입력을 한 번 평가합니다.
전체 스크립트를 실행하면 다음과 유사한 내용이 인쇄됩니다.
Test Accuracy: 0.966667정확도 결과는 약간 다를 수 있지만 90 % 이상이어야합니다. 상대적으로 작은 데이터 세트는 나쁘지 않습니다!
새 샘플 분류
견적 기의 predict () 메소드를 사용하여 새 견본을 분류하십시오. 예를 들어,이 두 가지 새로운 꽃 샘플이 있다고 가정 해보십시오.
| Sepal Length | Sepal Width | Petal Length | Petal Width |
|---|---|---|---|
| 6.4 | 3.2 | 4.5 | 1.5 |
| 5.8 | 3.1 | 5.0 | 1.7 |
predict () 메서드를 사용하여 해당 종을 예측할 수 있습니다. predict는 목록으로 쉽게 변환 될 수있는 dicts 생성자를 반환합니다. 다음 코드는 클래스 예측을 검색하고 인쇄합니다.
# Classify two new flower samples.
new_samples = np.array(
[[6.4, 3.2, 4.5, 1.5],
[5.8, 3.1, 5.0, 1.7]], dtype=np.float32)
predict_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"x": new_samples},
num_epochs=1,
shuffle=False)
predictions = list(classifier.predict(input_fn=predict_input_fn))
predicted_classes = [p["classes"] for p in predictions]
print(
"New Samples, Class Predictions: {}\n"
.format(predicted_classes))결과는 다음과 같습니다.
New Samples, Class Predictions: [1 2]따라서 모델은 첫 번째 샘플이 Iris versicolor이고 두 번째 샘플은 Iris virginica라고 예측합니다.
추가 리소스
tf.estimator를 사용하여 선형 모델을 만드는 방법에 대한 자세한 내용은 TensorFlow를 사용하는 대규모 선형 모델을 참조하십시오.
tf.estimator API를 사용하여 사용자의 Estimator를 빌드하려면 tf.estimator에서 Estimator 만들기를 확인하십시오.
브라우저에서 신경망 모델링 및 시각화를 실험하려면 Deep Playground를 확인하십시오.
신경 네트워크에 대한 고급 자습서는 길쌈 신경 네트워크 및 순환 신경 네트워크를 참조하십시오.
++++++
csv 파일을 원하는 데이터를 입력하면 간단히 판단하는 프로그램 및 그래프를 얻을 수 있습니다.
일정한 데이터를 가지고 판별하는 그래프 및 수식을 만들지 않고 원하는 것을 만들 수 있습니다.
글보다는 csv파일을 원하는 것으로 직접 수정하셔서 활용해보시면 더 빠른 이해를 하실 수 있습니다.
'Computer_IT > tensorflow' 카테고리의 다른 글
| [텐서플로우]인공지능 들여다보기(그래프 보기)Tensorboard) (0) | 2017.12.08 |
|---|---|
| tf.estimator로 입력 함수 작성하기 (0) | 2017.11.24 |
| TensorFlow Mechanics 101 (0) | 2017.08.24 |
| Deep MNIST for Experts ( 히든 레이어 버전) (0) | 2017.06.30 |
| [인공지능] Tensorflow 프로그래머 가이드부터 다시 시작하자. (0) | 2017.06.22 |
TensorFlow Mechanics 101
TensorFlow Mechanics 101
Code: tensorflow/examples/tutorials/mnist/
본 자습서의 목적은 TensorFlow를 사용하여(고전적인)MNIST데이터 세트를 사용하여 손으로 작성된 손가락을 사용하여 간단한 피드 포워드 신경 네트워크를 훈련하고 평가하는 방법입니다. 본 자습서의 대상은 TensorFlow를 사용하는 데 관심이 있는 숙련된 사용자를 위한 것입니다.
이러한 자습서는 일반적으로 기계 학습을 가르치기 위한 것이 아닙니다.
TensorFlow를 설치하기 위한 지침을 준수했는지 확인하십시오.
튜토리얼 파일
이 자습서는 다음 파일을 참조합니다.
파일 목적
mnist.py : 완전히 연결된 MNIST 모델을 빌드하는 코드.
fully_connected_feed.py : 피드 사전을 사용하여 다운로드 된 데이터 세트에 대해 빌드 된 MNIST 모델을 학습하는 기본 코드.
교육을 시작하려면 직접 fully_connected_feed.py 파일을 실행하기 만하면됩니다.
python fully_connected_feed.py데이터 준비
MNIST는 기계 학습의 전형적인 문제입니다. 문제는 회색으로 된 숫자 280x28픽셀 이미지를 보고이미지가 0에서 9까지의 숫자에 대해 나타내는 숫자를 판별하는 것입니다.
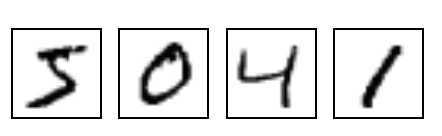
자세한 내용은 YanLecun의 MNIST페이지 또는 NBIST의 시각화를 참조하십시오.
(Yann LeCun's MNIST page or Chris Olah's visualizations of MNIST.)
다운로드.
런타임_데이터 처리()방법의 맨 위에 있는 경우 Input_data.reads_data_sets()함수가 로컬 교육 폴더로 다운로드된 데이터를 다운로드하여 DataSet인스턴스를 반환합니다.
data_sets = input_data.read_data_sets(FLAGS.train_dir, FLAGS.fake_data)참고 : fake_data 플래그는 단위 테스트 목적으로 사용되며 판독기에서 무시할 수 있습니다.
데이터 집합 목적
data_sets.train 55000 이미지 및 레이블, 기본 교육용.
data_sets.validation 5000 개의 이미지 및 레이블, 교육 정확도의 반복 검증.
data_sets.test 훈련 된 정확도의 최종 테스트를 위해 10000 개의 이미지 및 레이블.
입력 및 자리 표시 자
placeholder_inputs () 함수는 입력의 모양을 정의하는 두 개의 tf.placeholder 연산을 생성합니다.이 연산은 batch_size를 포함하여 나머지 그래프와 실제 훈련 예제가 입력됩니다.
images_placeholder = tf.placeholder(tf.float32, shape=(batch_size,
mnist.IMAGE_PIXELS))
labels_placeholder = tf.placeholder(tf.int32, shape=(batch_size))또한 트레이닝 루프에서 전체 이미지 및 레이블 데이터 세트가 각 단계의 batch_size에 맞게 슬라이스되고 이러한 자리 표시 자 연산과 일치 한 다음 feed_dict 매개 변수를 사용하여 sess.run () 함수로 전달됩니다.
그래프 작성
데이터의 자리 표시자를 만든 후 그래프는 3 단계 패턴 인 추론 (), 손실 () 및 학습 ()에 따라 mnist.py 파일에서 작성됩니다.
inference () - 예측을하기 위해 네트워크를 앞으로 돌리는 데 필요한만큼 그래프를 만듭니다.
loss () - 손실을 생성하는 데 필요한 연산을 추론 그래프에 추가합니다.
training () - 그라디언트를 계산하고 적용하는 데 필요한 연산을 손실 그래프에 추가합니다.
추론
inference () 함수는 출력 예측을 포함하는 텐서를 반환하는 데 필요한만큼 그래프를 작성합니다.
이미지 자리 표시자를 입력으로 사용하고 ReLU 활성화가있는 완전히 연결된 레이어와 출력 로짓을 지정하는 10 개의 노드 선형 레이어가 그 위에 빌드됩니다.
각 계층은 해당 범위 내에서 작성된 항목의 접두사로 사용되는 고유 한 tf.name_scope 아래에 작성됩니다.
with tf.name_scope('hidden1'):정의 된 범위 내에서 각 레이어에서 사용되는 가중치와 바이어스는 원하는 모양으로 tf.Variable 인스턴스에 생성됩니다.
weights = tf.Variable(
tf.truncated_normal([IMAGE_PIXELS, hidden1_units],
stddev=1.0 / math.sqrt(float(IMAGE_PIXELS))),
name='weights')
biases = tf.Variable(tf.zeros([hidden1_units]),
name='biases')예를 들어, hidden1 범위에서 생성 된 경우 weights 변수에 고유 한 이름이 "hidden1 / weights"가됩니다.
각 변수에는 초기화 작업이 주어진다.
이 가장 일반적인 경우, 가중치는 tf.truncated_normal로 초기화되고 2 차원 텐서의 모양이 주어지면 가중치가 연결되는 레이어의 단위 수를 나타내는 첫 번째 흐림과 수를 나타내는 두 번째 흐림이 표시됩니다 가중치가 연결되는 계층의 단위. hidden1이라는 첫 번째 레이어의 경우, 가중치가 이미지 입력을 hidden1 레이어에 연결하기 때문에 크기는 [IMAGE_PIXELS, hidden1_units]입니다. tf.truncated_normal 초기화 프로그램은 주어진 평균 및 표준 편차로 임의의 분포를 생성합니다.
그런 다음 바이어스를 tf.zeros로 초기화하여 모든 0 값으로 시작하도록하고 그 모양은 연결되는 레이어의 단위 수입니다.
그래프의 세 가지 주요 작업 - 숨겨진 레이어에 대해 tf.matmul 및 로그에 대해 하나의 추가 tf.matmul을 포함하는 두 개의 tf.nn.relu ops가 차례로 생성되고 각 인스턴스에는 각각 별도의 tf.Variable 인스턴스가 생성됩니다 입력 자리 표시 자의 이전 텐서 또는 이전 레이어의 출력 텐서.
hidden1 = tf.nn.relu(tf.matmul(images, weights) + biases)
hidden2 = tf.nn.relu(tf.matmul(hidden1, weights) + biases)
logits = tf.matmul(hidden2, weights) + biases마지막으로 출력을 포함하는 로그 텐서가 반환됩니다.
손실
loss () 함수는 필요한 손실 작업을 추가하여 그래프를 작성합니다.
먼저 labels_placeholder의 값이 64 비트 정수로 변환됩니다. 그런 다음 tf.nn.sparse_softmax_cross_entropy_with_logits op가 추가되어 labels_placeholder에서 1- 핫 레이블을 자동으로 생성하고 inference () 함수의 출력 로그를 1- 핫 레이블과 비교합니다.
labels = tf.to_int64(labels)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=labels, logits=logits, name='xentropy')그런 다음 tf.reduce_mean을 사용하여 일괄 처리 차원 (첫 번째 차원)에서 교차 엔트로피 값을 전체 손실로 평균화합니다.
loss = tf.reduce_mean(cross_entropy, name='xentropy_mean')그리고 나서 손실 값을 포함 할 텐서가 반환됩니다.
노트 : 교차 엔트로피는 정보 이론의 아이디어로, 실제로 사실 인 것을 감안할 때 신경망의 예측을 얼마나 나쁘게 생각하는지 설명 할 수 있습니다. 자세한 내용은 블로그 게시물 Visual Information Theory (http://colah.github.io/posts/2015-09-Visual-Information/)를 참조하십시오.
훈련
training () 함수는 Gradient Descent를 통해 손실을 최소화하는 데 필요한 연산을 추가합니다.
먼저 loss () 함수에서 손실 텐서를 취하여 tf.summary.FileWriter (아래 참조)와 함께 사용할 때 이벤트 파일에 요약 값을 생성하는 연산 인 tf.summary.scalar로 전달합니다. 이 경우 요약이 기록 될 때마다 손실의 스냅 샷 값을 방출합니다.
tf.summary.scalar('loss', loss)다음으로, 요청 된 학습 속도로 그라데이션을 적용하는 tf.train.GradientDescentOptimizer를 인스턴스화합니다.
optimizer = tf.train.GradientDescentOptimizer(learning_rate)그런 다음 글로벌 교육 단계에 대한 카운터를 포함하는 단일 변수를 생성하고 tf.train.Optimizer.minimize op는 시스템의 학습 가능한 가중치를 업데이트하고 전역 단계를 증가시키는 데 사용됩니다. 이 작업은 관습에 따라 train_op이라고하며, 한 단계의 교육 (아래 참조)을 유도하기 위해 TensorFlow 세션에서 실행해야하는 작업입니다.
global_step = tf.Variable(0, name='global_step', trainable=False)
train_op = optimizer.minimize(loss, global_step=global_step)모델 교육
일단 그래프가 작성되면 fully_connected_feed.py의 사용자 코드에 의해 제어되는 루프에서 반복적으로 트레이닝되고 평가 될 수 있습니다.
그래프
run_training () 함수의 맨 위에는 내장 된 모든 op가 기본 전역 tf.Graph 인스턴스와 연관되어 있음을 나타내는 명령과 함께 python이 있습니다.
with tf.Graph().as_default():tf.Graph는 그룹으로 함께 실행될 수있는 작업 모음입니다. 대부분의 TensorFlow 사용은 단일 기본 그래프에만 의존해야합니다.
여러 그래프를 사용하는보다 복잡한 용도는 가능하지만이 간단한 자습서의 범위를 벗어납니다.
세션
모든 빌드 준비가 완료되고 필요한 모든 작업이 생성되면 그래프 실행을위한 세션이 만들어집니다.
sess = tf.Session()
또는 세션을 범위 지정을 위해 with 블록으로 생성 할 수 있습니다.
with tf.Session() as sess:세션에 대한 빈 매개 변수는이 코드가 기본 로컬 세션에 연결 (또는 아직 생성되지 않은 경우 생성)한다는 것을 나타냅니다.
세션을 생성 한 직후, 모든 tf.Variable 인스턴스는 초기화 op에서 tf.Session.run을 호출하여 초기화됩니다.
init = tf.global_variables_initializer()
sess.run(init)tf.Session.run 메서드는 매개 변수로 전달 된 op (s)에 해당하는 그래프의 전체 하위 집합을 실행합니다. 이 첫 번째 호출에서 init op는 변수의 초기화 코드 만 포함하는 tf.group입니다. 나머지 그래프는 여기에서 실행되지 않습니다. 그것은 아래의 교육 과정에서 발생합니다.
학습 루프
세션으로 변수를 초기화 한 후 교육이 시작될 수 있습니다.
사용자 코드는 단계별 교육을 제어하며 유용한 교육을 수행 할 수있는 가장 단순한 루프는 다음과 같습니다.
for step in xrange(FLAGS.max_steps):
sess.run(train_op)그러나이 자습서는 이전 단계에서 생성 된 자리 표시 자와 일치시키기 위해 각 단계의 입력 데이터를 슬라이스해야한다는 점에서 약간 더 복잡합니다.
그래프 피드
각 단계에서 코드는 단계에 대한 교육을위한 예제 세트를 포함하는 피드 사전을 생성하며,이 단계는 해당 인스턴스가 나타내는 자리 표시 자 연산에 의해 입력됩니다.
fill_feed_dict () 함수에서 주어진 DataSet은 이미지와 레이블의 다음 batch_size 세트에 대해 쿼리되고 자리 표시 자와 일치하는 tensors는 다음 이미지와 레이블을 포함하여 채워집니다.
images_feed, labels_feed = data_set.next_batch(FLAGS.batch_size,
FLAGS.fake_data)
그런 다음 키와 자리 표시자를 나타내는 파이썬 사전 객체가 생성되고 대표적인 피드 텐서가 값으로 제공됩니다.
feed_dict = {
images_placeholder: images_feed,
labels_placeholder: labels_feed,
}이것은 sess.run () 함수의 feed_dict 매개 변수로 전달되어이 단계의 학습에 대한 입력 예제를 제공합니다.
상태 확인
이 코드는 실행 호출에서 가져올 두 값을 지정합니다 : [train_op, loss].
for step in xrange(FLAGS.max_steps):
feed_dict = fill_feed_dict(data_sets.train,
images_placeholder,
labels_placeholder)
_, loss_value = sess.run([train_op, loss],
feed_dict=feed_dict)가져올 값은 두 가지이므로 sess.run ()은 두 항목이 포함 된 튜플을 반환합니다. 가져올 값 목록에있는 각 Tensor는 반환 된 튜플의 numpy 배열에 해당하며이 단계에서이 텐서 값이 채워집니다. train_op은 출력 값이없는 Operation이기 때문에 반환 된 튜플의 해당 요소는 None이므로 버려집니다. 그러나 모델이 훈련 중에 분기되면 손실 텐서의 값은 NaN이 될 수 있으므로이 값을 로깅에 사용합니다.
NaN 없이도 교육이 잘 진행된다고 가정하면 교육 과정에서 100 단계마다 간단한 상태 텍스트를 인쇄하여 사용자에게 교육 상태를 알릴 수 있습니다.
if step % 100 == 0:
print('Step %d: loss = %.2f (%.3f sec)' % (step, loss_value, duration))상태 시각화
TensorBoard에서 사용되는 이벤트 파일을 내보내려면 그래프 작성 단계에서 모든 요약 (이 경우 하나만 포함)이 단일 텐서로 수집됩니다.
summary = tf.summary.merge_all()
그리고 나서 세션이 생성 된 후 tf.summary.FileWriter가 인스턴스화되어 그래프 자체와 요약 값을 모두 포함하는 이벤트 파일을 작성할 수 있습니다.
summary_writer = tf.summary.FileWriter(FLAGS.train_dir, sess.graph)
마지막으로, 이벤트 파일은 요약이 평가 될 때마다 새 요약 값으로 업데이트되고 출력이 작성자의 add_summary () 함수에 전달됩니다.
summary_str = sess.run(summary, feed_dict=feed_dict)
summary_writer.add_summary(summary_str, step)이벤트 파일을 작성하면 Training 폴더에 대해 TensorBoard를 실행하여 요약의 값을 표시 할 수 있습니다.
참고 : Tensorboard를 작성하고 실행하는 방법에 대한 자세한 내용은 함께 제공되는 Tensorboard : Visualizing Learning을 참조하십시오. Tensorboard: Visualizing Learning.
검사 점 저장(체크포인트 저장)
추후 교육이나 평가를 위해 모델을 나중에 복원하는 데 사용할 수있는 검사 점 파일을 내보내려면 tf.train.Saver를 인스턴스화합니다.
saver = tf.train.Saver()
트레이닝 루프에서는 tf.train.Saver.save 메소드가 정기적으로 호출되어 모든 트레이닝 가능한 변수의 현재 값을 사용하여 검사 점 파일을 트레이닝 디렉토리에 씁니다.
saver.save(sess, FLAGS.train_dir, global_step=step)
나중에 추후에 thetf.train.Saver.restore 메소드를 사용하여 모델 매개 변수를 다시로드하여 교육을 재개 할 수 있습니다.
saver.restore(sess, FLAGS.train_dir)모델 평가
천 단계마다이 코드는 교육 및 테스트 데이터 세트 모두에 대해 모델을 평가하려고 시도합니다. do_eval () 함수는 교육, 유효성 검사 및 테스트 데이터 집합에 대해 세 번 호출됩니다.
print('Training Data Eval:')
do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.train)
print('Validation Data Eval:')
do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.validation)
print('Test Data Eval:')
do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.test)더 복잡한 사용법은 대개 상당한 양의 하이퍼 매개 변수 튜닝 후에 만 확인되도록 data_sets.test를 격리합니다. 그러나 간단한 MNIST 문제 때문에 모든 데이터에 대해 평가합니다.
평가 그래프 작성
교육 루프를 시작하기 전에 평가 () 함수는 mnist.py에서 loss () 함수와 동일한 logits / labels 매개 변수를 사용하여 evaluation () 함수를 호출하여 작성해야합니다.
eval_correct = mnist.evaluation(logits, labels_placeholder)
evaluation () 함수는 단순히 true 레이블이 K 가장 가능성있는 예측에서 발견 될 수있는 경우 각 모델 출력을 자동으로 득점 할 수있는 tf.nn.in_top_k op를 생성합니다. 이 경우 K의 값을 1로 설정하여 실제 레이블 인 경우 올바른 예측 만 고려합니다.
eval_correct = tf.nn.in_top_k(logits, labels, 1)평가 출력
그런 다음 feed_dict를 채우고 eval_correct op에 대해 sess.run ()을 호출하여 지정된 데이터 집합에서 모델을 평가하는 루프를 만들 수 있습니다.
for step in xrange(steps_per_epoch):
feed_dict = fill_feed_dict(data_set,
images_placeholder,
labels_placeholder)
true_count += sess.run(eval_correct, feed_dict=feed_dict)
true_count 변수는 in_top_k op가 올바른 것으로 판단한 모든 예측을 누적합니다. 거기에서 정밀도는 총 사례 수로 단순히 나누어 계산할 수 있습니다.
precision = true_count / num_examples
print(' Num examples: %d Num correct: %d Precision @ 1: %0.04f' %
(num_examples, true_count, precision))'Computer_IT > tensorflow' 카테고리의 다른 글
| tf.estimator로 입력 함수 작성하기 (0) | 2017.11.24 |
|---|---|
| [텐서플로우] CSV 활용하기/ 간단한 판별 AI 만들기 (0) | 2017.10.10 |
| Deep MNIST for Experts ( 히든 레이어 버전) (0) | 2017.06.30 |
| [인공지능] Tensorflow 프로그래머 가이드부터 다시 시작하자. (0) | 2017.06.22 |
| [인공지능] 초급 손글씨 판별하기 (MNIST For ML Beginners) (0) | 2017.06.14 |
Deep MNIST for Experts ( 히든 레이어 버전)
Deep MNIST for Experts (전문가를위한 딥 MNIST)
TensorFlow는 대규모 수치 계산을 수행하는 강력한 라이브러리입니다. 탁월한 과제 중 하나는 심 신경 네트워크를 구현하고 교육하는 것입니다. 이 튜토리얼에서 우리는 TensorFlow 모델의 기본 빌딩 블록을 배우면서 깊은 컨볼 루션 MNIST 분류자를 생성합니다.
이 소개는 신경망과 MNIST 데이터 세트에 익숙하다고 가정합니다. 그들과 배경이 없다면, 초보자를위한 소개를 확인하십시오. 시작하기 전에 반드시 TensorFlow를 설치하십시오.
About this tutorial
이 튜토리얼의 첫 번째 부분에서는 Tensorflow 모델의 기본 구현 인 mnist_softmax.py코드에서 어떤 일이 일어나는지 설명합니다. 두 번째 부분에서는 정확성을 높이는 몇 가지 방법을 보여줍니다.
이 튜토리얼의 각 코드 스 니펫을 복사하여 Python 환경에 붙여 넣거나, 완전히 구현 된 깊은 네트를 mnist_deep.py 에서 다운로드 할 수 있습니다.
이 튜토리얼에서 우리가 달성 할 수있는 것 :
-이미지의 모든 픽셀을 관찰하여 MNIST 숫자를 인식하는 모델 인 softmax 회귀 함수를 만듭니다.
-Tensorflow를 사용하여 수천 가지 사례를 "조사"하여 숫자를 인식하도록 모델을 교육합니다 (첫 번째 Tensorflow 세션을 실행하여 수행)
-테스트 데이터로 모델의 정확성을 확인하십시오.
-결과를 향상시키기 위해 다중 컨볼 루션 신경망을 구축, 훈련 및 테스트합니다.
Setup
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)import tensorflow as tf
sess = tf.InteractiveSession()x = tf.placeholder(tf.float32, shape=[None, 784])
y_ = tf.placeholder(tf.float32, shape=[None, 10])Variables
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))sess.run(tf.global_variables_initializer())Predicted Class and Loss Function
y = tf.matmul(x,W) + bcross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y))Train the Model
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)for _ in range(1000):
batch = mnist.train.next_batch(100)
train_step.run(feed_dict={x: batch[0], y_: batch[1]})Evaluate the Model (모델 평가)
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))print(accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels}))Build a Multilayer Convolutional Network
멀티 레이어 컨볼 루션 네트워크 구축
MNIST에서 92 % 정확도를 얻는 것은 좋지 않습니다. 그것은 거의 당황스럽게도 나빴습니다. 이 섹션에서는 아주 단순한 모델에서 중간 정도의 복잡한 것, 즉 작은 콘볼 루션 신경 네트워크로 점프 할 것입니다. 이것은 우리에게 99.2 %의 정확성을 줄 것입니다. 예술 수준은 아니지만 존경 할 만합니다.
무게 초기화
이 모델을 만들려면 많은 가중치와 편향을 만들어야합니다. 일반적으로 대칭 분리를 위해 소량의 잡음을 사용하여 가중치를 초기화하고 0 기울기를 방지해야합니다. 우리가 ReLU(ReLU) 뉴런을 사용하고 있기 때문에, "죽은 뉴런"을 피하기 위해 약간 긍정적 인 초기 바이어스로 초기화하는 것이 좋습니다. 모델을 빌드하는 동안이 작업을 반복적으로 수행하는 대신, 우리를 위해이 작업을 수행하는 두 가지 편리한 기능을 만들어 보겠습니다.
+여기서 ReLU가 나오는데 CNN 및 점점 들어갈 수록 많이 사용되는 용어입니다.
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)회선 및 풀링
TensorFlow는 또한 컨볼 루션 및 풀링 작업에 많은 유연성을 제공합니다. 경계를 어떻게 처리할까요? 우리의 보폭은 무엇입니까? 이 예에서는 항상 바닐라 버전을 선택합니다. 우리의 컨볼 루션은 1의 보폭을 사용하며 출력이 입력과 동일한 크기가되도록 0으로 채워집니다. 우리의 풀링은 2x2 블록을 넘어서 평범한 오래된 최대 풀링입니다. 코드를보다 깨끗하게 유지하려면 이러한 연산을 함수로 추상화합시다.
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')첫 번째 콘볼 루션 레이어
이제 첫 번째 레이어를 구현할 수 있습니다. 컨볼 루션 (convolution)과 최대 풀링 (max pooling)으로 구성됩니다. 컨볼 루션은 각 5x5 패치에 대해 32 개의 기능을 계산합니다. 그것의 체중 텐서는 [5, 5, 1, 32]의 모양을 가질 것입니다. 처음 두 차원은 패치 크기이고, 다음은 입력 채널 수이고, 마지막은 출력 채널 수입니다. 각 출력 채널에 대한 구성 요소가있는 바이어스 벡터도 갖게됩니다.
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])레이어를 적용하기 위해 먼저 x와 4d 텐서의 형태를 바꾸고 두 번째 및 세 번째 차원은 이미지 너비와 높이에 해당하고 최종 차원은 색상 채널 수에 해당합니다.
x_image = tf.reshape(x, [-1, 28, 28, 1])우리는 x_image와 체중 텐서를 곱하고, 바이어스를 추가하고, ReLU 함수를 적용하고, 마지막으로 최대 풀을 적용합니다. max_pool_2x2 메소드는 이미지 크기를 14x14로 줄입니다.
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)두 번째 컨벌루션 레이어
깊은 네트워크를 구축하기 위해이 유형의 여러 레이어를 쌓습니다. 두 번째 레이어에는 각 5x5 패치에 대해 64 개의 기능이 있습니다.
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)조밀하게 연결된 레이어
이미지 크기가 7x7로 축소되었으므로 전체 이미지에서 처리 할 수 있도록 1024 개의 뉴런이있는 완전히 연결된 레이어를 추가합니다. 우리는 풀링 레이어에서 텐서를 벡터 묶음으로 변형하고, 가중치 행렬을 곱하고, 바이어스를 추가하고, ReLU를 적용합니다.
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)DropOut
초과 맞춤을 줄이기 위해 판독 레이어 앞에 드롭 아웃을 적용합니다. 우리는 드롭 아웃 중에 뉴런의 출력이 유지 될 확률에 대한 자리 표시자를 만듭니다. 이것은 우리가 훈련 중에 dropout을 켜고 시험하는 동안 turn off 할 수있게 해줍니다. TensorFlow의 tf.nn.dropout op는 마스킹 외에도 스케일링 뉴런 출력을 자동으로 처리하므로 드롭 아웃은 추가 스케일링 없이도 작동합니다 .
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)판독 레이어
마지막으로 위의 한 계층 softmax 회귀와 마찬가지로 계층을 추가합니다.
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2차이점은 다음과 같습니다.
-가파른 그라데이션 하강 옵티 마이저를보다 정교한 ADAM 옵티 마이저로 대체 할 것입니다.
-feed_dict에 추가 매개 변수 keep_prob를 포함시켜 드롭 아웃 속도를 제어합니다.
-우리는 교육 과정에서 매 100 번째 반복에 로깅을 추가 할 것입니다.
또한 tf.InteractiveSession보다는 tf.Session을 사용할 것입니다. 이렇게하면 그래프를 만드는 과정 (모델 선택)과 그래프를 평가하는 과정 (모델 피팅)이 더 잘 분리됩니다. 일반적으로 더 깨끗한 코드를 만듭니다. tf.Session은 with 블록 내에서 만들어 지므로 블록이 종료되면 자동으로 삭제됩니다.
이 코드를 자유롭게 실행하십시오. 2 만 건의 교육 반복 작업을 수행하며 프로세서에 따라 다소 시간이 걸릴 수 있습니다 (최대 30 분 소요).
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(20000):
batch = mnist.train.next_batch(50)
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x: batch[0], y_: batch[1], keep_prob: 1.0})
print('step %d, training accuracy %g' % (i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print('test accuracy %g' % accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))이 코드를 실행 한 후 최종 테스트 세트 정확도는 약 99.2 % 여야합니다.
우리는 TensorFlow를 사용하여 매우 정교한 심층 학습 모델을 빠르고 쉽게 작성, 교육 및 평가하는 방법을 배웠습니다.
1 :이 작은 컨볼 루션 네트워크의 경우 성능은 실제로 드롭 아웃 유무와 거의 동일합니다. 드롭 아웃은 종종 과잉을 줄이는 데 효과적이지만 매우 큰 신경 네트워크를 학습 할 때 가장 유용합니다.
+ Relu와 Dropout을 활용하여 심층 신경망을 연결하는 방법 및 히든레이어를 활용하여 서로 연결된 네트워크망을 구성하는 방법을 간단하게 나왔습니다. 추후의 CNN 을 참고하게 된다면 더 많은 레이어 구성 및 복잡하지만 단순하게 구성하는 방법의 튜토리얼이 나옵니다.
출처 : https://www.tensorflow.org/get_started/mnist/pros
'Computer_IT > tensorflow' 카테고리의 다른 글
| [텐서플로우] CSV 활용하기/ 간단한 판별 AI 만들기 (0) | 2017.10.10 |
|---|---|
| TensorFlow Mechanics 101 (0) | 2017.08.24 |
| [인공지능] Tensorflow 프로그래머 가이드부터 다시 시작하자. (0) | 2017.06.22 |
| [인공지능] 초급 손글씨 판별하기 (MNIST For ML Beginners) (0) | 2017.06.14 |
| [인공지능] tensorflow 시작 튜토리얼 2 : tf.train API (0) | 2017.06.05 |
[인공지능] Tensorflow 프로그래머 가이드부터 다시 시작하자.
튜토리얼은 따라 가겠는데... 전혀 감이 안잡힌다... 그래서 Get started 다음에 있는
프로그래머 가이드 부분에서부터 다시 시작하겠습니다.
Variables: Creation, Initialization, Saving, and Loading
이 문서는 다음 TensorFlow 클래스를 참조합니다. API에 대한 전체 설명은 참조 설명서 링크를 참조하십시오.
- The
tf.Variableclass. - The
tf.train.Saverclass.
Creation (창조)
변수를 만들면 초기 값으로 Tensor를 Variable () 생성자에 전달합니다. TensorFlow는 상수 또는 임의 값에서 초기화에 자주 사용되는 텐서를 생성하는 연산 모음을 제공합니다.
이러한 모든 작업에는 텐서의 모양을 지정해야합니다. 그 모양은 자동으로 변수의 모양이됩니다.
변수는 일반적으로 고정 된 모양을 갖지만 TensorFlow는 변수를 변경하는 고급 메커니즘을 제공합니다.
# Create two variables.
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35),
name="weights")
biases = tf.Variable(tf.zeros([200]), name="biases")tf.Variable ()을 호출하면 그래프에 몇 가지 연산이 추가됩니다.
- 변수 값을 보유하는 변수 op.
- 변수를 초기 값으로 설정하는 이니셜 라이저 op. 이것은 실제로 tf.assign op입니다.
- 예제의 biases 변수에 대한 0과 같은 초기 값에 대한 연산도 그래프에 추가됩니다.
tf.Variable () 값에 의해 반환되는 값은 Python 클래스 tf.Variable의 인스턴스입니다.
Device placement
변수는 with tf.device (...) : 블록을 사용하여 특정 장치가 생성 될 때 특정 장치에 고정 될 수 있습니다.
# Pin a variable to CPU.
with tf.device("/cpu:0"):
v = tf.Variable(...)
# Pin a variable to GPU.
with tf.device("/gpu:0"):
v = tf.Variable(...)
# Pin a variable to a particular parameter server task.
with tf.device("/job:ps/task:7"):
v = tf.Variable(...)NOTE
tf.Variable.assign 및 tf.train.Optimizer의 매개 변수 업데이트 작업과 같은 변수를 변경하는 작업은 변수와 동일한 장치에서 실행해야합니다. 호환되지 않는 장치 배치 지시문은 이러한 작업을 생성 할 때 무시됩니다.
장치 배치는 복제 된 설정에서 실행할 때 특히 중요합니다. 복제 된 모델의 장치 구성을 단순화 할 수있는 장치 기능에 대한 자세한 내용은 tf.train.replica_device_setter 를 참조하십시오.
Initialization(초기화)
또는 체크 포인트 파일에서 변수 값을 복원 할 수도 있습니다 (아래 참조).
변수 이니셜 라이저를 실행할 op를 추가하려면 tf.global_variables_initializer ()를 사용하십시오. 모델을 완전히 구성하고 세션에서 시작한 후에 만 op를 실행하십시오.
# Create two variables.
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35),
name="weights")
biases = tf.Variable(tf.zeros([200]), name="biases")
...
# Add an op to initialize the variables.
init_op = tf.global_variables_initializer()
# Later, when launching the model
with tf.Session() as sess:
# Run the init operation.
sess.run(init_op)
...
# Use the model
...Initialization from another Variable (다른 변수로부터의 초기화)
때때로 다른 변수의 초기 값에서 변수를 초기화해야합니다. tf.global_variables_initializer ()가 추가 한 연산은 모든 변수를 병렬로 초기화하므로 필요할 때 조심해야합니다.
다른 변수의 값에서 새 변수를 초기화하려면 다른 변수의 initialized_value () 속성을 사용하십시오. 초기화 된 값을 새 변수의 초기 값으로 직접 사용할 수도 있고 다른 변수로 사용하여 새 변수의 값을 계산할 수도 있습니다.
# Create a variable with a random value.
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35),
name="weights")
# Create another variable with the same value as 'weights'.
w2 = tf.Variable(weights.initialized_value(), name="w2")
# Create another variable with twice the value of 'weights'
w_twice = tf.Variable(weights.initialized_value() * 2.0, name="w_twice")Custom Initialization(사용자 정의 초기화)
편의 함수 tf.global_variables_initializer ()는 op를 추가하여 모델의 모든 변수를 초기화합니다. 변수의 명시적인 목록을 전달하여 tf.variables_initializer로 초기화 할 수도 있습니다. 변수가 초기화되었는지 확인하는 것을 포함하여 다른 옵션에 대해서는 변수 설명서( Variables Documentation)를 참조하십시오.
Saving and Restoring (저장 및 복원)
모델을 저장하고 복원하는 가장 쉬운 방법은 tf.train.Saver 객체를 사용하는 것입니다. 생성자는 그래프의 모든 변수 또는 지정된 목록의 그래프에 저장 및 복원 작업을 추가합니다. saver 객체는 이러한 ops를 실행하고 체크 포인트 파일에 대한 쓰기 또는 읽기 경로를 지정하는 메서드를 제공합니다.
그래프가없는 모델 체크 포인트를 복원하려면 먼저 메타 그래프 파일에서 그래프를 가져와야합니다 (일반적인 확장자는 .meta 임). 이것은 tf.train.import_meta_graph를 사용하여 수행됩니다.이 그래프는 복원을 수행 할 수있는 Saver를 반환합니다.
+meta 데이터 파일이 그래프라고 합니다.... 이제까지 pb가 그래프인줄 알고 있었는데... ㅎㅎㅎ 역시 기초가 탄탄해야 하는 것 같습니다.
Checkpoint Files
변수는 대개 변수 이름에서 텐서 값까지의 맵을 포함하는 바이너리 파일에 저장됩니다.
Saver 개체를 만들 때 검사 점 파일에서 변수의 이름을 선택적으로 선택할 수 있습니다. 기본적으로 각 변수에 대해 tf.Variable.name 속성 값을 사용합니다.
체크 포인트에있는 변수를 이해하려면 inspect_checkpoint 라이브러리, 특히 print_tensors_in_checkpoint_file 함수를 사용할 수 있습니다.
Saving Variables (변수 저장하기)
모델의 모든 변수를 관리하려면 tf.train.Saver ()를 사용하여 Saver를 작성하십시오.
# Create some variables.
v1 = tf.Variable(..., name="v1")
v2 = tf.Variable(..., name="v2")
...
# Add an op to initialize the variables.
init_op = tf.global_variables_initializer()
# Add ops to save and restore all the variables.
saver = tf.train.Saver()
# Later, launch the model, initialize the variables, do some work, save the
# variables to disk.
with tf.Session() as sess:
sess.run(init_op)
# Do some work with the model.
..
# Save the variables to disk.
save_path = saver.save(sess, "/tmp/model.ckpt")
print("Model saved in file: %s" % save_path)Restoring Variables(변수 복원)
동일한 Saver 개체가 변수를 복원하는 데 사용됩니다. 파일에서 변수를 복원 할 때는 미리 변수를 초기화 할 필요가 없습니다.
# Create some variables.
v1 = tf.Variable(..., name="v1")
v2 = tf.Variable(..., name="v2")
...
# Add ops to save and restore all the variables.
saver = tf.train.Saver()
# Later, launch the model, use the saver to restore variables from disk, and
# do some work with the model.
with tf.Session() as sess:
# Restore variables from disk.
saver.restore(sess, "/tmp/model.ckpt")
print("Model restored.")
# Do some work with the model
...Choosing which Variables to Save and Restore (저장 및 복원 할 변수 선택)
tf.train.Saver ()에 인수를 전달하지 않으면 세이버는 그래프의 모든 변수를 처리합니다. 이들 각각은 변수가 생성 될 때 전달 된 이름으로 저장됩니다.
검사 점 파일에서 변수의 이름을 명시 적으로 지정하는 것이 유용한 경우가 있습니다. 예를 들어 "weights"라는 이름의 변수를 가진 모델을 교육했을 수도 있습니다.이 변수의 값은 "params"라는 새 변수에 복원하려는 값입니다.
또한 모델에 사용되는 변수의 하위 집합 만 저장하거나 복원하는 것이 유용한 경우도 있습니다. 예를 들어 5 개의 레이어가있는 신경망을 훈련했을 수 있습니다. 이제 6 개의 레이어로 새 모델을 학습하고 이전에 학습 된 모델의 5 개 레이어에서 새 모델의 처음 5 개 레이어로 매개 변수를 복원 할 수 있습니다.
tf.train.Saver () 생성자에 파이썬 사전을 전달하여 저장할 이름과 변수를 쉽게 지정할 수 있습니다. keys는 사용할 이름이고, value는 관리 할 변수입니다.
Notes:
- 모델 변수의 여러 하위 집합을 저장하고 복원해야하는 경우 원하는만큼의 보호기 개체를 만들 수 있습니다. 동일한 변수가 여러 세이버 객체에 나열 될 수 있으며 세이버 restore () 메소드가 실행될 때만 해당 값이 변경됩니다.
- 세션 시작시 모델 변수의 하위 집합 만 복원하는 경우 다른 변수에 대해 초기화 연산을 실행해야합니다. 자세한 정보는 tf.variables_initializer를 참조하십시오.
# Create some variables.
v1 = tf.Variable(..., name="v1")
v2 = tf.Variable(..., name="v2")
...
# Add ops to save and restore only 'v2' using the name "my_v2"
saver = tf.train.Saver({"my_v2": v2})
# Use the saver object normally after that.
...'Computer_IT > tensorflow' 카테고리의 다른 글
| TensorFlow Mechanics 101 (0) | 2017.08.24 |
|---|---|
| Deep MNIST for Experts ( 히든 레이어 버전) (0) | 2017.06.30 |
| [인공지능] 초급 손글씨 판별하기 (MNIST For ML Beginners) (0) | 2017.06.14 |
| [인공지능] tensorflow 시작 튜토리얼 2 : tf.train API (0) | 2017.06.05 |
| [인공지능] TensorFlow 시작하기 (설치 이후 첫 튜토리얼) (0) | 2017.05.22 |
[인공지능] 초급 손글씨 판별하기 (MNIST For ML Beginners)
이 게시글은 기계 학습과 기계 학습 모두에 새롭게 등장하는 독자를 위한 것입니다.
MNIST가 무엇인지 이미 알고 있다면 softmax( multinomial logistic)회귀이 무엇인지를 알 수 있으며, 이는 보다 빠른 속도의 자습서를 선호할 수 있습니다.
튜토리얼을 시작하기 전에 반드시 TensorFlow를 설치해야 합니다.
프로그래밍하는 법을 배울 때,"HelloWorld"는 "HelloWorld"를 인쇄하는 것과 같은 전통을 가지고 있습니다. 프로그래밍이 HelloWorld를 하는 것은 이번 튜토리얼과 같은 문맥입니다.
MNIST는 간단한 컴퓨터 비전 데이터 세트입니다. 이는 다음과 같이 손으로 작성한 숫자의 이미지로 구성됩니다.
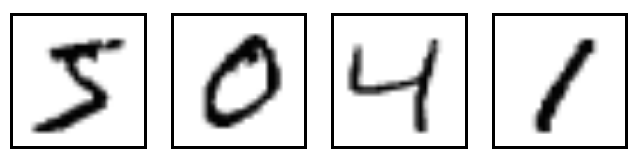
또한 각 이미지에 대한 라벨이 포함되어 있으며, 각 이미지에 해당하는 숫자를 알려 줍니다.
예를 들어 위 이미지의 레이블은 5,0,4,1입니다.
이 튜토리얼에서, 우리는 이미지를 관찰하고 그들이 어떤 숫자인지 예측할 수 있도록 모델을 훈련시킬 것입니다.
우리의 목표는 최첨단 성능을 발휘하는 정교한 모델을 훈련시키는 것이 아니라, 나중에 할 수 있도록 코드를 부여하는 것입니다!--하지만 발가락을 사용하여 발가락 부분을 찍는 것이 낫다.
이와 같이 우리는 매우 단순한 모델로 시작할 것입니다. 바로 Softmax 회귀라는 회귀 모델입니다.
+ 즉, 나중에 훈련시킨 모델들을 가져오는 원리들을 파악 및 softmax 회귀 모델을 알아가는 부분인 것 같습니다.
이 튜토리얼의 실제 코드는 매우 짧으며, 모든 재미 있는 것들은 세줄로 되어 있습니다.하지만, 그것 이면의 아이디어들을 이해하는 것은 매우 중요하다.이것 때문에, 우리는 매우 신중하게 코드를 완성할 것입니다.
본 자습서는 mnist_softmax.py 라인 코드에서 발생하는 일련의 설명, 라인별로 설명합니다.
본 자습서는 다음을 비롯하여 몇가지 다른 방법으로 사용할 수 있습니다.
1) 각 줄의 설명을 통해 읽을 수 있는 대로 각 코드를 라인별로 구분하여 라인 업으로 복사하고 붙여 넣으십시오.
2) 설명서를 읽기 전에 전체 mnist_softmax.py Python 파일을 실행하고 이 자습서를 사용하여 명확하지 않은 코드를 이해할 수 있도록 합니다.
수행할 내용:
1)데이터 중복 제거 기술에 대한 자세한 내용 및 데이터 중복 제거 기술에 대해 알아보기.
2)이미지의 모든 픽셀을 보는 데 기반하여 자릿수를 인식하는 기능을 생성합니다.
3)TensorFlow를 사용하여 모델을 " 보기"로 인식하여 모델을 식별하고, 수천개의 예제를 실행할 수 있도록 합니다.
4)테스트 데이터를 통해 모델의 정확도를 점검하십시오.
The MNIST Data
MNIST 데이터는 Yann LeCun의 웹 사이트에서 호스팅 됩니다.
이 자습서에서 코드를 복사하고 붙여 넣는 경우, 여기서 데이터를 자동으로 다운로드하고 읽을 수 있는 코드 두줄로 시작하십시오.
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)MNIST 데이터는 세 부분으로 나뉩니다. 즉, 교육 데이터의 55,000개의 데이터 포인트( mnist.train), 테스트 데이터의 10,000포인트( mnist.test), 검증 데이터의 5,000포인트( mnist.validation)등이 있습니다.
이 세분류는 매우 중요합니다. 우리가 배워야 할 것은 우리가 배우지 못한 것을 확실히 할 수 있는 별개의 데이터를 가지고 있다는 것입니다.
앞서 언급한 바와 같이, 모든 MNIST 데이터 포인트에는 두개의 파트가 있습니다. 즉, 손으로 작성한 숫자와 해당 라벨의 이미지입니다.
우리는 이미지"x"와 라벨"y"를 부를 것입니다. 교육 세트 및 테스트 세트에는 이미지 및 해당 라벨이 모두 포함되어 있습니다. 예를 들어 교육용 이미지는 mnist.train.images이며, 교육용 레이블은 mnist.train.labels.입니다.
각 이미지는 28픽셀 x28픽셀입니다. NAT은 다음과 같은 다양한 수치로 해석할 수 있습니다.
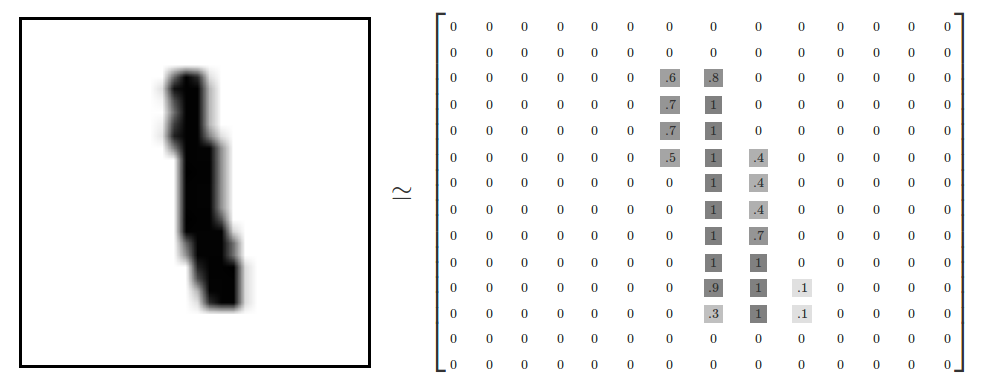
우리는 이 배열을 28x28의 벡터의 벡터로 평평하게 만들 수 있다. 우리가 이미지들 사이에 일관성을 유지하는 한, 우리가 어떻게 배열할지는 중요하지 않습니다.
이러한 관점에서 볼 때, MNIST 이미지는 매우 풍부한 구조(경고:시각화 집약적 시각화)를 가진 벡터 기반 벡터 공간의 수많은 포인트일 뿐입니다.
평평한 데이터에서 이미지의 2D구조에 대한 정보가 삭제됩니다. 최고의 컴퓨터 비전 방법은 이 구조를 이용하는 거죠. 그리고 우리는 나중에 튜토리얼을 쓸 것입니다. 그러나 우리가 여기서 사용할 간단한 방법은 다음과 같습니다.
결과적으로 mnist.train.images는 55000( n-dimensional, 784, ])의 텐서이다. 첫번째 차원은 영상 목록에 있는 색인이며 두번째 차원은 각 영상의 각 픽셀에 대한 인덱스입니다.텐서( tensor)의 각 항목은 특정 영상의 특정 화소에 대해 0과 1사이의 화소 강도이다.

각 그림 MNIST의 각 이미지에는 해당 이미지에 그려진 숫자를 나타내는 0~9사이의 숫자가 있습니다.
본 자습서를 위해 저희는 라벨을 "one-hot 벡터"라고 부르고자 합니다. 벡터 기반 벡터는 대부분의 차원에서 0이며, 단일 차원의 1차원이다. 이 경우 n번째 숫자는 n번째 치수의 1개의 벡터로 표현됩니다.예를 들어, 3은[0,0,0,0,0,0,0,0,0,0]입니다. 결과적으로 mnist.train.labels는[ 55000,10]kg의 부동 소수 점 배열이다.
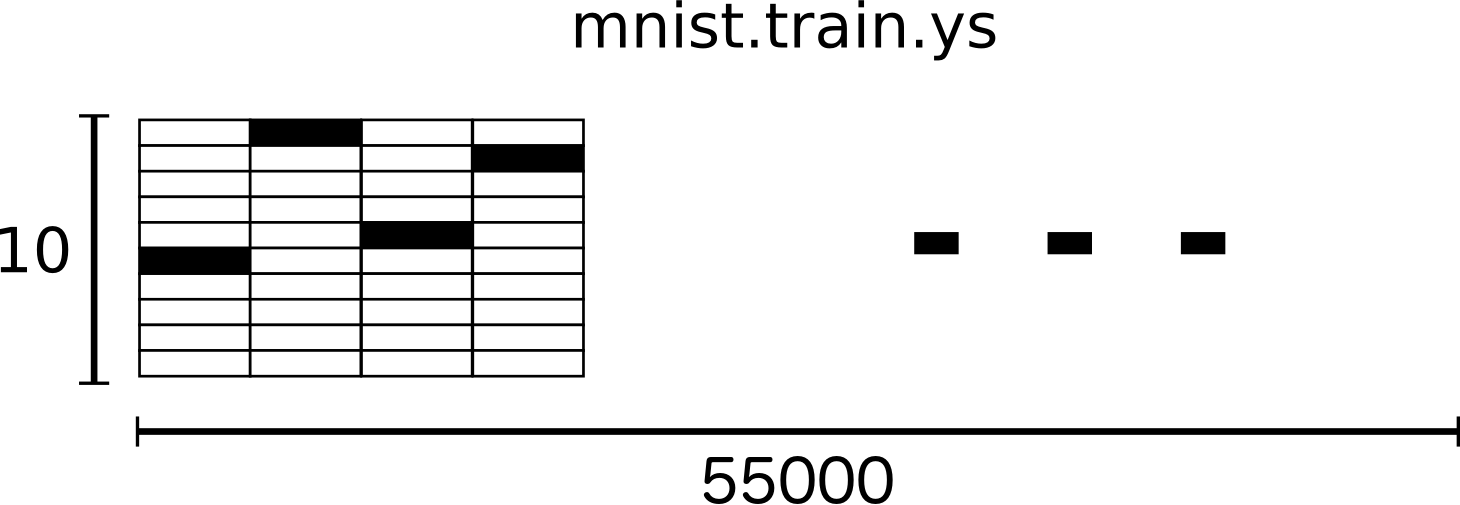
우리는 이제 실제로 모델을 만들 준비가 됐어요!
Softmax Regressions
파이썬을 사용하여 효율적인 숫자 계산을 하기 위해서, 우리는 보통 Python곱셈기와 같은 비싼 작업을 하는 NumPy 같은 라이버리을 사용한다. 다른 언어로 구현된 매우 효율적인 코드이다.
불행히도, 모든 운영 체제로 전환하는 데는 여전히 많은 오버 헤드가 존재할 수 있습니다.
이 오버 헤드는 특히 데이터 전송에 높은 비용이 들 수 있는 분산된 방식이나 분산된 방식으로 계산하려는 경우에 특히 나쁩니다.
TensorFlow는 또한 Python을 없애기 위해 많은 노력을 하지만, 이러한 오버 헤드를 피하기 위해 한 걸음 더 나아 간다.
Python은 파이썬을 사용하여 독립적으로 운영하는 것을 대신하는 대신에 파이선을 사용하여 운영되는 상호 작용 작업의 그래프에 대해 설명합니다.(이와 같은 접근 방식은 몇개의 기계 학습 라이브러리에서 볼 수 있습니다.)
TensorFlow를 사용하려면 먼저 가져와야 합니다.
import tensorflow as tfimport tensorflow as tf우리는 상징적 변수를 조작하여 이러한 상호 작용 운영을 설명한다. 다음을 생성합니다.
x = tf.placeholder(tf.float32, [None, 784])x는 특정한 가치가 아니다. 이것은 자리 표시자입니다. 우리가 계산대에서 계산할 때 우리가 입력할 가치가 있는 값입니다.
우리는 각각의 MNIST 이미지들을 784-dimensional 벡터로 바꿀 수 있는 숫자를 입력할 수 있기를 원합니다.
우리는 이것을 부동 소수 점 이하의 부동 소수 점 숫자의 2차원 텐서( 784)로 표현한다. (여기서는 치수가 어떤 길이라도 될 수 있음을 의미한다.)
우리는 또한 모델에 대한 체중(Weights)과 편견(Biases)이 필요합니다. 우리는 이것들을 추가 투입하는 것을 상상할 수 있지만, TensorFlow는 그것을 다루는 더 나은 방법을 가지고 있습니다. Variable
Variable는 상호 작용의 상호 작용에 대한 TensorFlow의 그래프에서 수정 가능한 수정 가능한 텐서이다.
그것은 계산에 의해 사용되고 심지어 수정될 수도 있다. 기계 학습 애플리케이션의 경우 일반적으로 모델 매개 변수는 변수 변수가 됩니다.
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))우리는 변수의 초기 값을 tf.Variable의 초기 값으로 줌으로써 이 변수를 생성합니다. 이 경우에는 W과 b을 tf.zeros 0으로 나눕니다.
우리는 W와 b를 배울 것이기 때문에, 그것들이 처음에는 그다지 중요하지 않다.
W는[ 784,10]의 형태를 가지고 있습니다. 왜냐하면 우리는 벡터의 벡터 벡터를 곱하기 위해 다른 등급의 벡터 벡터를 생성하기 위해 벡터 벡터를 곱하고 싶습니다.b는 출력에 추가할 수 있도록[10]의 모양을 가지고 있다.
이제 모델을 구현할 수 있습니다. 그것을 정의하는데 한줄만 걸려요!
y = tf.nn.softmax(tf.matmul(x, W) + b)첫째로, 우리는 x, W, W의 표현으로 x를 곱합니다.
이것은 우리가 곱셈 부호를 가지고 있는 우리의 방정식으로, 우리가 여러개의 입력을 가진 2D텐서를 다루는 작은 속임수로 우리의 방정식에 넣은 것에서 힌트를 얻었다.
그리고 나서 우리는 b를 추가하고, 마침내 tf.nn.softmax.를 적용한다.
바로 그거에요. 몇번의 짧은 설치 후에 모델을 정의할 수 있는 선이 하나밖에 없었습니다.
그것은 TensorFlow가 특별히 쉽게 회귀할 수 있도록 설계되었기 때문이 아니다.
그것은 기계 학습 모델에서부터 물리학 시뮬레이션에 이르기까지 많은 숫자의 수치 연산을 묘사하는 매우 유연한 방법입니다.
그리고 일단 정의된 대로, 우리의 모델은 컴퓨터의 CPU, GPUs, 심지어는 심지어 전화기로도 작동할 수 있습니다!
Training
모델을 훈련시키기 위해서, 우리는 모델이 좋은 것이 무엇인지를 의미하는 것을 정의해야 합니다.
실제로, 기계 학습에서는 전형적으로 모델이 나쁘다는 것을 의미합니다.
우리는 이것을 원가 혹은 손실이라 부르며, 그것은 우리의 모델이 원하는 결과로부터 얼마나 멀리 떨어져 있는지를 나타냅니다.
우리는 에러를 최소화하려고 합니다. 에러 마진이 적을수록 우리의 모델은 더 좋습니다.
모델의 분실을 결정하기 위한 매우 일반적이고 매우 훌륭한 기능은 "cross-entropy"라고 불립니다.
정보 이론은 정보 이론에서 정보 압축 코드에 대해 생각하는 것에서 기인하지만, 도박에서부터 기계 학습에 이르기까지 많은 분야에서 중요한 아이디어가 된다. 다음과 같이 정의됩니다.

여기서 y는 예측 가능한 확률 분포이며 y ′는 실제 분포(자릿수 라벨을 사용한 one-hot 벡터)이다.
대략적으로, cross-entropy는 우리의 예측이 진실을 설명하는 데 얼마나 비효율적인지를 측정하고 있다.
cross-entropy에 대한 자세한 내용은 본 자습서의 범위를 벗어나지만 이해할 만한 가치가 충분히 있습니다.
cross-entropy를 구현하려면 먼저 새 자리 표시자를 추가하여 올바른 답을 입력해야 합니다.
y_ = tf.placeholder(tf.float32, [None, 10])우리는 cross-entropy 기능을 구현할 수 있다. :
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))첫째, tf.log는 y의 각 요소의 대수를 계산한다. 다음으로 y-y의 원소를 곱하고 y^y(y)와 같은 원소를 곱한다.
그런 다음 tf.reduce_sum는 reduction_indices=[1 매개 변수로 인해 y의 두번째 치수에 해당하는 요소를 추가합니다.
마지막으로, tf.reduce_mean는 배치의 모든 예제에 대한 평균을 계산합니다.
소스 코드에서는 이 공식을 사용하지 않습니다. 숫자가 불안정하기 때문입니다. 그 대신에 unnormalized(x, W)+b(x, W)에 softmax_cross_entropy_with_logits를 tf.nn.softmax_cross_entropy_with_logits에 적용한다.
이는 보다 수치적으로 안정적인 기능을 통해 내부적으로 softmax 활성화를 계산합니다. 코드를 사용하는 경우 대신 tf.nn.softmax_cross_entropy_with_logits를 사용하는 것을 고려해 보십시오.
이제 우리가 원하는 것이 무엇인지 알 수 있으므로, 우리가 그것을 하기 위해 TensorFlow를 훈련시키는 것은 매우 쉬워요.
왜냐하면 TensorFlow는 당신의 계산의 전체 그래프를 알고 있기 때문입니다. 자동화 알고리즘을 사용하여 변수가 손실되는 손실에 어떻게 영향을 미치는지 효율적으로 결정할 수 있습니다.
그런 다음 최적화 알고리즘을 적용하여 변수를 수정하고 손실을 줄일 수 있습니다.
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)이 경우에, 우리는 TensorFlow에게 0.5의 학습 속도로 구배 하강 알고리즘을 사용하여 cross_entropy를 최소화할 것을 요청한다.경사 하강은 간단한 절차입니다. 여기서 TensorFlow는 단순히 각 변수를 비용을 감소시키는 방향으로 조금씩 돌립니다. 하지만 TensorFlow는 여러가지 다른 최적화 알고리즘을 제공합니다. 만약 한개만 한다면 하나의 선을 조정하는 것만큼 간단합니다.
TensorFlow가 실제로 여기서 수행하는 것은 backpropagation와 경사도 하강을 구현하는 그래프에 새로운 연산을 추가하는 것입니다. 그런 다음, 단일 작업을 수행합니다. 단, 작동 시 기울기 하강 훈련을 수행하여 변수를 약간 수정하고 손실을 줄입니다.
이제 InteractiveSession에서 모델을 시작할 수 있습니다.
sess = tf.InteractiveSession()먼저 생성한 변수를 초기화하기 위한 작업을 생성해야 합니다.
tf.global_variables_initializer().run()훈련을 시작합시다--훈련 스텝은 1000번입니다!
for _ in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})각 단계마다 100개의 무작위 데이터 포인트가 배치되어 있습니다. 교육 세트에서 백개의 랜덤 데이터 포인트를 얻을 수 있습니다. 우리는 배치 데이터에서 자리 표시자를 대체하기 위해 train_step 데이터를 실행한다.
무작위 데이터의 소량 배치를 확률적 훈련이라 부르며 이 경우 확률적 경사 하강 하강이다. 이상적으로는, 우리는 모든 훈련 과정을 위해 모든 데이터를 사용하고 싶습니다. 왜냐하면 우리는 우리가 해야 할 일을 더 잘 이해할 수 있기 때문입니다. 하지만 그것은 비쌉니다. 따라서, 우리는 매번마다 다른 하위 집합을 사용합니다. 이것을 하는 것은 싸고 이로운 점도 많다.
Evaluating Our Model
우리의 모델은 얼마나 잘 되나요?
글쎄요, 우선 정확한 라벨을 어디에 뒀는지 알아냅시다. tf.argmax는 어떤 축을 따라 가장 높은 진입률의 지수를 나타내는 매우 유용한 기능이다. 예를 들어, tf.argmax(y, 1)은 각 입력에 대해 가장 가능성이 높은 라벨이며, tf.argmax(y_, 1)은 정확한 라벨로 표시된다. 우리는 우리의 예측이 진실과 일치하는지를 확인하기 위해 tf.equal를 사용할 수 있다.
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))그것은 우리에게 booleans 리스트를 제공한다. 정확한 비율을 결정하기 위해, 우리는 부동 소수 점 숫자를 선택한 다음 평균을 취한다. 예를 들어,[True, False, True, True]는 0.75가 될[1,0,1,1]이 됩니다.
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))마지막으로, 우리는 우리의 시험 데이타에 대한 정확성을 요구한다.
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))이는 약 92%여야 합니다.
good ? 어떤가요? 글쎄, 그렇진 않아. 사실, 그것은 꽤나 나빠요. 이것은 우리가 매우 단순한 모델을 사용하고 있기 때문입니다.
약간의 깊이를 가지고 있으면 97%까지 갈 수 있어요. 최고의 모델들은 99.7%이상의 정확도를 달성할 수 있습니다! ( 자세한 내용은 이 결과 목록을 참조하십시오.)
중요한 것은 우리가 이 모델에서 배운 것입니다. 그럼에도 불구하고, 만약 여러분이 이러한 결과에 대해 조금 더 우울하다면, 우리가 훨씬 더 잘하는 다음 튜토리얼을 통해 더 정교한 모델을 만드는 방법을 배워 보세요!
출처 : https://www.tensorflow.org/get_started/mnist/beginners
추후 다음 튜토리얼을 하기 전에 실제 돌린 장면을 포함해서 올리도록 하겠습니다.
'Computer_IT > tensorflow' 카테고리의 다른 글
| Deep MNIST for Experts ( 히든 레이어 버전) (0) | 2017.06.30 |
|---|---|
| [인공지능] Tensorflow 프로그래머 가이드부터 다시 시작하자. (0) | 2017.06.22 |
| [인공지능] tensorflow 시작 튜토리얼 2 : tf.train API (0) | 2017.06.05 |
| [인공지능] TensorFlow 시작하기 (설치 이후 첫 튜토리얼) (0) | 2017.05.22 |
| 인공지능의 입문 Tensorflow를 설치해보자. (0) | 2017.05.04 |